1. 领域背景与文献
文献英文标题:TUG1: a potential endogenous reference gene for long noncoding RNA quantification in blood-based studies;发表期刊:Biomarker Research;影响因子:未公开;研究领域:长链非编码RNA生物标志物检测标准化。
领域共识:长链非编码RNA是近年来生命科学领域的研究热点,其具有调控基因表达的功能,且表达具有疾病特异性,同时可通过血液等非侵入性样本稳定检出,因此在疾病诊断、预后评估、疗效监测等临床场景中具备极高的应用潜力。实时荧光定量聚合酶链反应(qPCR)是长链非编码RNA定量检测的首选技术,但RNA实验流程中样本采集、冻融循环、RNA提取、模板投入量、酶促反应效率等多个环节均可能引入技术变异,若无法有效消除这类变异,会掩盖真实的生物学表达差异,导致研究结果出现偏差。
传统的长链非编码RNA定量研究多使用信使RNA作为内参进行标准化,但信使RNA与长链非编码RNA在生化性质、转录调控模式、表达丰度范围等方面均存在显著差异,这类跨RNA类型的内参可能引入额外的标准化误差,领域内已逐渐形成应使用同类型RNA作为内参的共识。目前针对全血样本的长链非编码RNA内参筛选研究较少,现有研究存在样本量小、未与传统信使RNA内参进行系统性能对比、缺乏多队列通用性验证等局限,尚未找到公认的稳定内参,极大限制了血液长链非编码RNA生物标志物研究的结果可靠性与临床转化效率。本研究针对这一领域空白,旨在系统性筛选适用于全血样本的稳定长链非编码RNA内参,为相关研究提供可靠的标准化方案,提升研究结果的可重复性与临床适用性。
2. 文献综述解析
作者在综述部分按“生物标志物应用潜力→定量技术痛点→现有标准化方案的局限性”的逻辑展开评述,系统性梳理了领域内现有研究的进展与不足。
现有研究已证实血液来源的长链非编码RNA可作为多种疾病的诊断、预后生物标志物,相关成果已在肿瘤、感染性疾病、心血管疾病等多个领域发表,充分证明了该类生物标志物的临床价值。实时荧光定量聚合酶链反应作为长链非编码RNA定量的金标准技术,其数据需进行标准化处理以消除技术噪声的必要性已被广泛认可,现有常用的内参稳定性评估方法包括geNorm、NormFinder、BestKeeper三种算法,三者分别从表达配对变异、组内组间变异、表达相关系数三个维度评估基因稳定性,联合使用可有效降低单一算法的评估偏差。
但现有研究仍存在明显局限性:首先,多数长链非编码RNA定量研究仍沿用传统信使RNA内参,未考虑两类RNA的性质差异对标准化结果的影响;其次,已有的少数长链非编码RNA内参筛选研究多针对特定组织或较小的样本队列,针对全血样本的大样本系统性筛选研究匮乏;最后,现有筛选出的候选内参通常缺乏多中心、多疾病队列的通用性验证,临床应用的可靠性不足。本研究的创新价值在于首次在大样本全血队列中完成84种长链非编码RNA的系统性筛选,同时纳入8种常用信使RNA内参进行性能头对头对比,且通过多个独立外部数据集验证候选内参的通用性,弥补了领域内全血样本长链非编码RNA内参缺乏的核心空白,研究结果可为后续所有基于血液的长链非编码RNA研究提供标准化参考。
3. 研究思路总结与详细解析
本研究的核心目标是筛选出在全血样本中表达稳定、标准化性能优异的长链非编码RNA内参,核心科学问题是哪些长链非编码RNA在全血样本中表达不受临床特征影响,且标准化性能优于传统信使RNA内参,整体技术路线遵循“候选基因表达谱检测→多算法稳定性评估→标准化性能验证→临床关联性分析→外部数据集交叉验证”的闭环逻辑,所有实验与分析流程均符合领域内相关技术规范。
3.1 候选基因表达谱检测
实验目的:检测候选长链非编码RNA与常用信使RNA内参在全血样本中的表达水平,筛选满足基本检测要求的候选基因,为后续稳定性评估提供可靠基础数据。
方法细节:研究队列纳入182例新冠病毒诱导的急性呼吸窘迫综合征幸存者的全血样本,经质控后最终180例样本的定量数据完整,纳入后续分析。采用逆转录定量聚合酶链反应(RT-qPCR)对84种候选长链非编码RNA和8种领域常用信使RNA内参的表达水平进行检测,预设的表达纳入标准为:所有样本中均稳定检出、最大定量循环值(Cq)<33、中位定量循环值<30,以确保候选内参的表达丰度足够满足临床检测的灵敏度需求。
结果解读:经筛选共有29种长链非编码RNA满足预设的表达纳入标准(n=180),其余55种长链非编码RNA因表达量过低、检出率不足被排除。文献未提及具体实验产品,领域常规使用总RNA提取试剂盒、逆转录试剂盒、实时荧光定量聚合酶链反应预混液及对应基因的引物探针类试剂完成相关检测。
3.2 候选基因表达稳定性评估
实验目的:基于满足表达标准的候选基因,通过多算法联合评估其表达稳定性,初步筛选出最具潜力的内参候选。
方法细节:采用领域内公认的三种内参稳定性评估算法geNorm、NormFinder和BestKeeper,分别对29种候选长链非编码RNA和8种信使RNA内参的表达稳定性进行计算并排名,内参筛选标准设定为“至少在两种算法中排名前三”,以保障筛选结果的可靠性。
结果解读:三种算法的评估结果显示,长链非编码RNA牛磺酸上调基因1(TUG1)在所有算法中均排名前列,其中geNorm算法中稳定性最高的是牛磺酸上调基因1与FGD5反义RNA1的配对组合,NormFinder和BestKeeper算法中稳定性最高的均为牛磺酸上调基因1,结合筛选标准最终确定牛磺酸上调基因1、FGD5反义RNA1和锌指反义RNA1为候选长链非编码RNA内参;信使RNA内参方面,geNorm算法中稳定性最高的是次黄嘌呤磷酸核糖转移酶1与肽基脯氨酰顺反异构酶A的配对组合,NormFinder算法中最高的是次黄嘌呤磷酸核糖转移酶1,BestKeeper算法中最高的是肽基脯氨酰顺反异构酶A,结合筛选标准确定次黄嘌呤磷酸核糖转移酶1、肽基脯氨酰顺反异构酶A、β2-微球蛋白为候选信使RNA内参。对应结果展示为图1,其中图A为候选长链非编码RNA的稳定性值统计,图C为候选信使RNA的稳定性值统计。
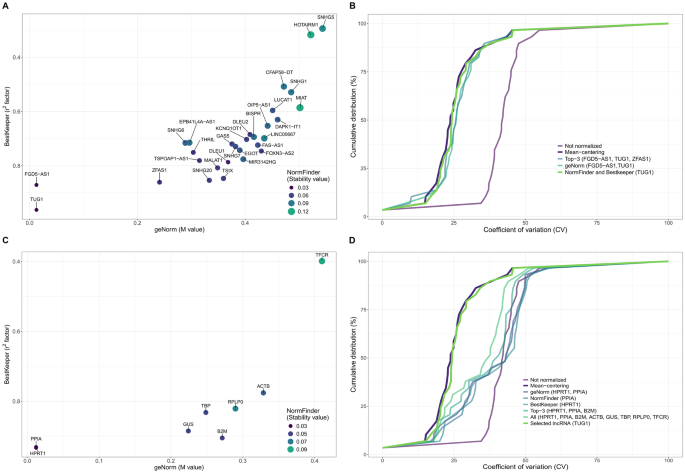
文献未提及具体实验产品,领域常规使用相关生物信息学分析软件完成稳定性计算与排名。
3.3 内参标准化性能验证
实验目的:验证筛选出的候选内参的实际标准化性能,与金标准方法及传统信使RNA内参进行头对头对比,确定最优内参。
方法细节:采用多种不同的标准化策略对长链非编码RNA表达数据集进行处理,包括未标准化、均值中心化(领域公认的标准化金标准方法)、单一候选长链非编码RNA、多个候选长链非编码RNA组合、单一候选信使RNA、多个候选信使RNA组合、所有8种信使RNA组合,通过比较不同策略处理后表达数据的变异系数累积分布,评估各策略对技术变异的消减效果,变异系数越小代表标准化性能越好。
结果解读:均值中心化作为金标准方法实现了最大程度的表达变异消减,而仅使用牛磺酸上调基因1单一内参进行标准化的变异消减效果与均值中心化相当,且显著优于所有其他测试的标准化策略,包括多个长链非编码RNA内参的组合、所有信使RNA内参相关的标准化策略。对应结果展示为图1的累积分布曲线,其中图B为不同长链非编码RNA标准化策略的变异系数累积分布,图D为包含信使RNA标准化策略的变异系数累积分布。文献未提及具体实验产品,领域常规使用相关统计分析软件完成数据处理与可视化。
3.4 牛磺酸上调基因1稳定性的补充验证
实验目的:进一步验证牛磺酸上调基因1作为内参的临床适用性与跨队列通用性,排除其表达受临床特征干扰的可能。
方法细节:首先分析牛磺酸上调基因1的表达水平与研究队列的各项临床变量、临床结局指标的关联性,评估其表达是否受患者临床特征影响;其次纳入四个独立的外部RNA测序数据集,包含健康人群、肌萎缩侧索硬化患者、急性心肌梗死患者、长新冠患者的全血样本,验证牛磺酸上调基因1在不同人群队列中的表达水平与稳定性。
结果解读:牛磺酸上调基因1的表达水平与研究队列的各项临床特征、临床结局均无显著关联(n=180,文献未明确提供具体P值),排除了其表达受疾病状态、人口学特征等因素干扰的可能;在四个外部独立数据集中,牛磺酸上调基因1均属于表达量最高、表达变异性最低的长链非编码RNA之列,进一步支持其作为全血样本长链非编码RNA内参的跨队列通用性。文献未提及具体实验产品,领域常规使用相关生物信息学分析工具完成数据集整合与关联分析。
4. Biomarker 研究及发现成果
本研究涉及的生物标志物为内参类生物标志物,即适用于全血样本长链非编码RNA定量的内参基因牛磺酸上调基因1,其筛选与验证遵循“大样本队列表达谱初筛→多算法稳定性复筛→标准化性能验证→临床关联性验证→多外部数据集交叉验证”的完整逻辑链条,结果可靠性高。
研究过程详述:牛磺酸上调基因1的表达检测样本来源为研究队列的全血样本,初筛方法为逆转录定量聚合酶链反应定量检测,满足所有样本均稳定检出、最大定量循环值<33、中位定量循环值<30的纳入标准(n=180);后续通过三种稳定性算法评估其表达稳定性,在所有算法中均排名第一;标准化性能验证显示其作为单一内参的变异消减效果与金标准均值中心化相当,显著优于传统信使RNA内参;临床关联性分析显示其表达与临床变量无显著关联;外部验证阶段在四个独立的全血RNA测序数据集中均表现出高表达、低变异的特征,验证了其通用性。文献未明确提供特异性与敏感性相关数据。
核心成果提炼:牛磺酸上调基因1可作为全血样本长链非编码RNA定量的首选内参基因,其标准化性能优于现有常用的信使RNA内参及其他候选长链非编码RNA,且作为单一内参使用即可达到接近金标准的标准化效果,无需使用多个内参组合,操作更简便、检测成本更低,无需复杂的计算步骤,可直接应用于常规临床检测流程。本研究首次在大样本全血队列中系统验证牛磺酸上调基因1作为长链非编码RNA内参的性能,为血液长链非编码RNA生物标志物研究的标准化提供了新的可靠选择,可有效提升相关研究结果的准确性与可重复性。统计学结果显示,牛磺酸上调基因1在三种稳定性算法中均排名第一,标准化后变异消减水平与均值中心组无显著差异(文献未明确提供具体P值),与临床变量无显著关联(文献未明确提供具体P值)。
本研究的优势在于队列表型明确、样本量大、筛选的长链非编码RNA面板覆盖范围广,保障了筛选结果的可靠性;局限性在于研究队列仅包含新冠病毒诱导的急性呼吸窘迫综合征幸存者,人群较为单一,且筛选的长链非编码RNA面板范围有限,后续需在不同疾病人群、多中心独立队列中进一步验证牛磺酸上调基因1作为内参的通用性,同时可纳入更多功能分类的长链非编码RNA进行筛选,降低内参与靶基因共调控的风险。推测:牛磺酸上调基因1的稳定表达特性可能与其参与基础细胞生命活动的持家基因功能相关,后续可进一步探索其在其他类型体液样本(如血浆、血清)中的适用性,拓展其应用场景。