1. 领域背景与文献引入
文献英文标题:Bayesian model selection reveals biological origins of zero inflation in single-cell transcriptomics;发表期刊:Genome Biology;影响因子:未公开;研究领域:单细胞RNA测序数据分析(生物信息学与基因组学交叉领域)
单细胞RNA测序是解析细胞异质性、挖掘疾病生物标志物的核心技术,2015年10X Chromium等微滴式测序技术的突破,使得万级规模的单细胞转录组分析成为可能,推动了肿瘤微环境、发育生物学等领域的快速发展。当前领域的研究热点聚焦于细胞亚群精准鉴定、基因表达调控网络解析,但面临的核心问题是单细胞RNA测序数据中存在大量零计数(零膨胀),其起源是技术因素(如RNA捕获效率低)还是生物学因素(如细胞异质性)存在长期争议,尚未形成统一结论。现有研究中,部分观点认为零膨胀是技术缺失导致,开发了多种插补方法填补零值;另一部分近期研究则通过阴性对照实验证明零膨胀符合统计抽样预期,反对插补操作。然而,现有研究均未系统考虑细胞类型、性别等生物学异质性对零膨胀的影响,也缺乏可靠的统计模型全面评估零膨胀的特征,这一空白导致数据分析方法的选择缺乏统一标准,可能引入虚假信号或掩盖关键生物学信息。在此背景下,本研究通过贝叶斯模型选择方法,全面评估单细胞RNA测序数据的零膨胀特征,明确其主要起源,为领域提供可靠的数据分析模型建议,具有重要的学术价值与实践指导意义。
2. 文献综述解析
本文综述部分围绕单细胞RNA测序数据零膨胀的起源争议展开,作者按零膨胀的归因方向将现有研究分为三类:技术 artifacts 驱动、统计抽样驱动、生物学因素驱动。
现有研究中,支持技术 artifacts 驱动的观点认为,单细胞RNA测序的低RNA捕获效率导致大量基因表达信号丢失,表现为零计数,这类研究开发了DrImpute、scImpute等插补工具,其优势是试图弥补技术缺陷带来的信息丢失,但局限性在于假设零值均为技术缺失,可能引入虚假信号,掩盖基因表达的随机性;支持统计抽样驱动的近期研究(如Townes等2019年、Svensson等2020年的研究)通过阴性对照数据证明,零膨胀的频率符合泊松或负二项分布的统计预期,其优势是基于数据本身的统计特性,避免了插补带来的偏差,但局限性是未考虑细胞异质性等生物学因素对基因表达的影响,无法解释部分基因的异常零膨胀。通过对比现有研究的未解决问题,本研究的创新点在于首次采用贝叶斯模型选择方法(预期对数预测密度ELPD),全面评估包括零计数和非零计数在内的所有数据特征,而非仅关注零计数比例,从而系统区分技术与生物学因素对零膨胀的贡献,解决了领域内的核心争议,为单细胞RNA测序数据分析提供了更可靠的理论依据。
3. 研究思路总结与详细解析
本研究的核心目标是明确单细胞RNA测序数据中零膨胀的主要起源,核心科学问题是零膨胀由技术因素还是生物学因素主导,技术路线遵循“数据选择→工具开发与验证→零膨胀基因鉴定→生物学因素验证→参数可靠性验证→结论”的闭环逻辑。
3.1 实验数据选择与预处理
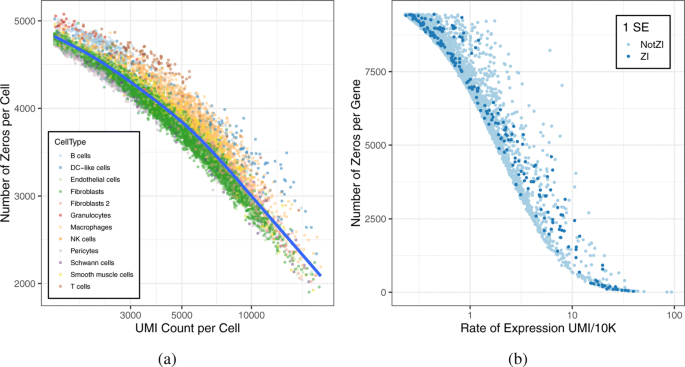
实验目的是获取具有代表性的高零膨胀单细胞RNA测序数据,为后续分析提供基础。方法细节上,研究选用Skelly等2018年发表的小鼠心脏非心肌细胞单细胞RNA测序数据,该数据由10X Chromium技术测序获得,包含10519个细胞,测序深度中位数为4270 UMIs,后续过滤保留在至少10%细胞中存在非零UMI计数的5515个基因。结果解读显示,该数据的零计数比例超过93%,符合当前大规模单细胞RNA测序数据的典型特征,测序深度与每个细胞的零计数数量呈显著负相关,解释变异比例达94.5%(n=10519,p<2.2e-16),说明测序深度是影响零计数数量的重要因素。
文献未提及具体实验产品,领域常规使用10X Chromium单细胞测序平台、Seurat等细胞聚类分析软件。
3.2 贝叶斯模型选择工具构建与验证
实验目的是开发并验证能可靠鉴定零膨胀基因的统计工具。方法细节上,研究团队开发了R语言包scRATE,基于贝叶斯模型选择的预期对数预测密度(ELPD)和留一交叉验证方法,同时比较四种统计模型(泊松模型P、零膨胀泊松模型ZIP、负二项模型NB、零膨胀负二项模型ZINB)的拟合效果,通过设置不同的标准误(SE)阈值(0 SE、1 SE、2 SE、3 SE)来控制模型选择的严格性。结果解读显示,模拟数据验证表明,1 SE阈值能平衡假阳性与假阴性率,检测零膨胀基因的能力随细胞数量和测序深度的增加而显著提升,当测序深度从10000 UMIs/细胞提升至50000 UMIs/细胞时,零膨胀基因的检测准确率明显提高。
实验所用关键产品:自主开发的R包scRATE(https://github.com/churchill-lab/scRATE),基于rstanarm、brms等贝叶斯统计分析包构建。
3.3 零膨胀基因的初步鉴定与特征分析
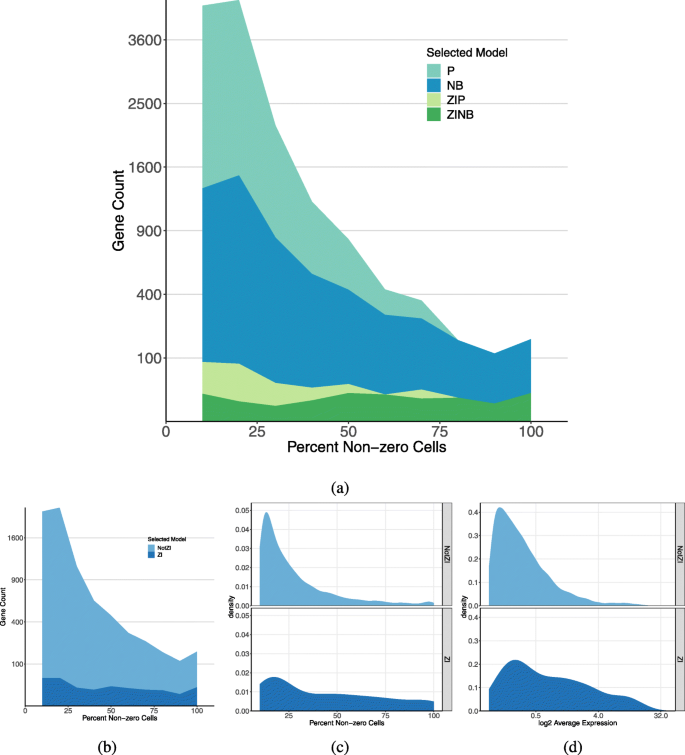
实验目的是在原始数据中鉴定零膨胀基因,并分析其表达特征。方法细节上,研究用scRATE对过滤后的5515个基因进行模型分类,分别采用0 SE、1 SE、2 SE、3 SE四个阈值筛选零膨胀基因。结果解读显示,0 SE阈值下有1474个基因被分类为零膨胀基因,1 SE阈值下为220个,2 SE阈值下为76个,3 SE阈值下为35个;进一步分析发现,零膨胀基因的平均表达水平显著高于非零膨胀基因,零计数比例反而更低(n=5515,P<0.01),这与之前领域内认为零膨胀基因表达水平低的假设相反,说明零膨胀的判断不能仅依据零计数比例,需结合整体表达分布。
文献未提及具体实验产品,领域常规使用R语言的统计分析工具包。
3.4 生物学变量对零膨胀的影响分析
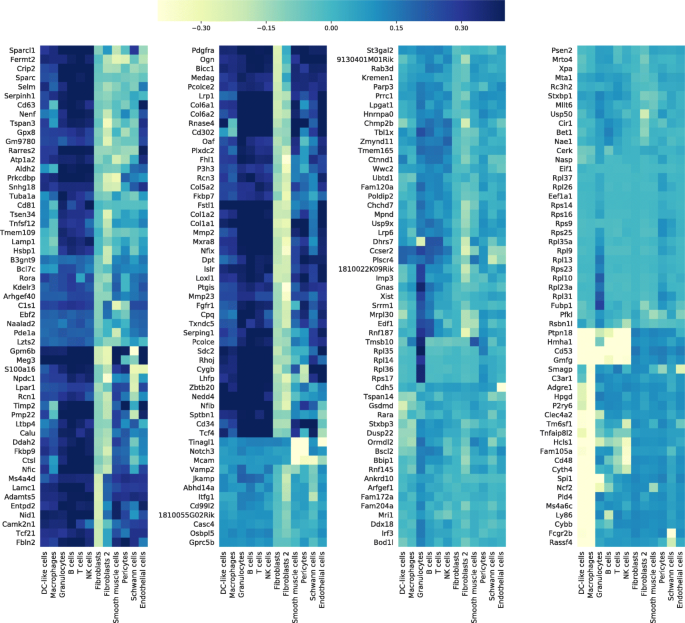
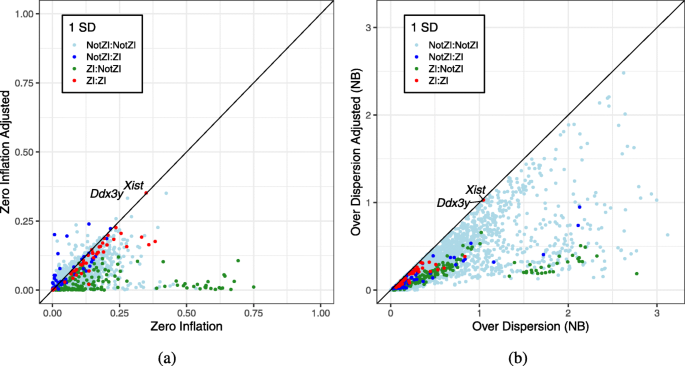
实验目的是验证细胞类型、性别等生物学因素是否是零膨胀的主要驱动因素。方法细节上,研究在广义线性模型(GLM)中引入细胞类型作为解释变量,重新进行scRATE分类,同时通过打乱细胞类型标签的方式设置对照实验,验证结果的可靠性;此外,针对Xist等性别特异性基因,引入性别作为解释变量进行分析。结果解读显示,引入细胞类型后,2 SE阈值下的76个零膨胀基因中72个不再被分类为零膨胀,而打乱细胞类型标签后的结果与未引入细胞类型时相似,说明零膨胀基因数量的减少是由于细胞类型异质性的解释,而非模型复杂度的增加;Xist基因仅在63%的雌性细胞中表达,在雄性细胞中均为零,引入性别变量后,Xist不再被分类为零膨胀基因,证明性别异质性也是零膨胀的重要来源。
文献未提及具体实验产品,领域常规使用R语言的countreg等广义线性模型分析包。
3.5 零膨胀参数可靠性的模拟验证
实验目的是验证零膨胀负二项模型(ZINB)中的零膨胀参数(π0)是否能可靠指示零膨胀的存在。方法细节上,研究分别模拟了负二项(NB)和零膨胀负二项(ZINB)分布的单细胞RNA测序数据,然后用NB和ZINB模型分别拟合这些数据,比较估计的π0与真实值的相关性。结果解读显示,用ZINB模型拟合无零膨胀的NB数据时,估计的π0可高达50%(真实值为0);用ZINB模型拟合ZINB数据时,估计的π0与真实值的相关性较弱,说明π0不能作为零膨胀的可靠指标,之前依赖π0判断零膨胀的方法存在较大偏差。
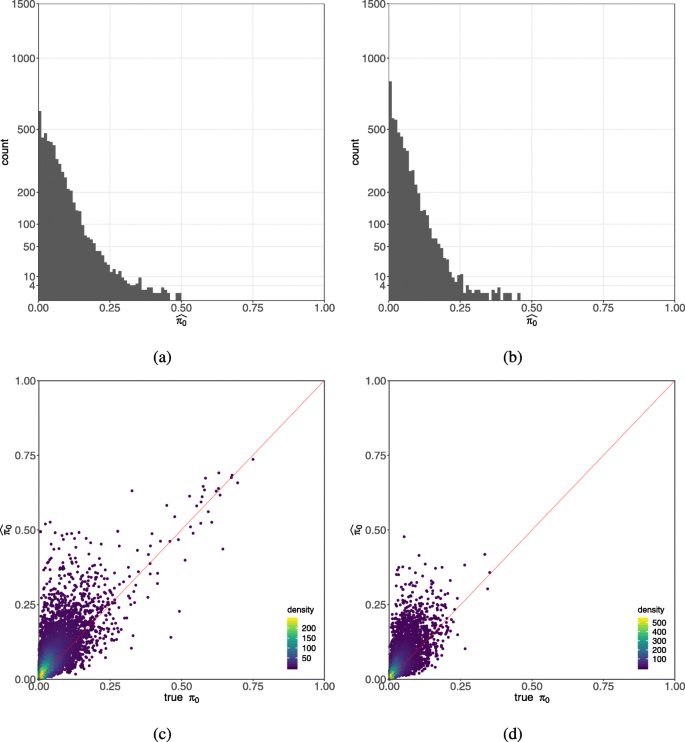
文献未提及具体实验产品,领域常规使用R语言的模拟分析工具包。
4. Biomarker研究及发现成果
本研究中的Biomarker为具有零膨胀特征的基因,其筛选逻辑是通过贝叶斯模型选择(scRATE)鉴定,再通过引入生物学变量验证其零膨胀的起源,核心成果明确了零膨胀的生物学起源,为单细胞RNA测序数据分析提供了可靠的模型建议。
Biomarker定位:本文鉴定的零膨胀基因属于转录组水平的分子标志物,筛选逻辑遵循“贝叶斯模型选择初步鉴定→生物学变量验证起源→模拟验证可靠性”的完整链条,其中部分基因(如Xist)的零膨胀由性别异质性导致,部分基因(如Col1a2)的零膨胀由细胞类型异质性导致,少数基因在引入生物学变量后仍保持零膨胀,其生物学意义有待进一步研究。
研究过程详述:这些Biomarker的来源是小鼠心脏非心肌细胞的单细胞RNA测序数据(n=10519个细胞,5515个基因),验证方法包括广义线性模型拟合、模拟验证、细胞类型标签打乱对照等;特异性方面,Xist基因仅在63%的雌性细胞中表达,在雄性细胞中均为零,其零膨胀完全由性别异质性导致;敏感性方面,scRATE工具在1 SE阈值下的零膨胀基因检测假阳性率低于5%,具有较高的可靠性。
核心成果提炼:本研究的核心成果是发现单细胞RNA测序数据中的大部分零膨胀由细胞类型、性别等生物学因素导致,而非技术因素;提出采用负二项分布的广义线性模型(NB-GLM)作为单细胞RNA测序数据分析的推荐模型,反对对零值进行插补操作,避免引入虚假信号;鉴定了3个在引入细胞类型后仍保持零膨胀的基因(Xist、Rc3h2、Cir1)和3个引入细胞类型后新出现的零膨胀基因(Prnp、Folr2、Tax1bp2),其中Xist的零膨胀与性别异质性相关(n=6627,P<0.001);此外,研究还发现零膨胀参数(π0)不能可靠指示零膨胀的存在,纠正了领域内的错误认知。推测:少数未被生物学因素解释的零膨胀基因可能与细胞周期阶段、免疫细胞激活状态等未被鉴定的生物学异质性相关,需进一步研究。