1. 领域背景与文献引入
文献英文标题:Integrated models of blood protein and metabolite enhance the diagnostic accuracy for Non-Small Cell Lung Cancer;发表期刊:Biomarker Research;影响因子:未公开;研究领域:非小细胞肺癌(NSCLC)血液蛋白与代谢物整合诊断模型研究。
肺癌是全球癌症死亡的首要原因,其中非小细胞肺癌(NSCLC)占比约85%。早期NSCLC(I期)患者的5年生存率可达61%,但超过70%的患者确诊时已处于晚期(III/IV期),5年生存率仅13%。因此,开发精准、无创的早期筛查与鉴别诊断方法是NSCLC研究的关键方向。目前,低剂量计算机断层扫描(LDCT)是NSCLC常用的筛查手段,但存在辐射暴露风险,且难以准确区分肺部恶性肿瘤与良性肺疾病(如肺结核、肺炎性结节)。血液生物标志物因具有无创、成本低、可重复性好等优势,成为NSCLC早期检测的研究热点。然而,单一生物标志物(如经典肿瘤标志物CEA、CYFRA21-1)的敏感性和特异性有限,且基于基因组、转录组的研究仅能反映潜在的分子变化,无法直接体现疾病的实际表型。蛋白质组(proteome)作为表型的直接决定因素,代谢组(metabolome)作为基因组和蛋白质组的下游产物,更能准确反映疾病状态,但目前整合血浆蛋白质组与代谢组的NSCLC诊断研究仍较少,且缺乏包含健康对照(HC)、NSCLC患者及良性肺疾病(BPD)患者的大样本验证。基于此,本研究旨在通过串联质谱标签-液相色谱-串联质谱(TMT-LC-MS/MS)技术解析NSCLC患者血浆差异蛋白,结合代谢组(氨基酸、胆汁酸)与经典肿瘤标志物,利用机器学习算法建立整合诊断模型,提升NSCLC筛查与鉴别的准确性。
2. 文献综述解析
文献综述围绕“NSCLC早期诊断的需求→现有方法的局限→血液生物标志物的研究现状→整合蛋白组与代谢组的必要性”展开逻辑评述。首先,作者强调NSCLC早期诊断的重要性,指出LDCT等传统方法的辐射风险与良恶性鉴别难题;接着,回顾血液生物标志物的研究进展,指出单基因、单蛋白或单代谢物标志物的敏感性/特异性不足,且基因组、转录组研究无法直接反映蛋白功能与代谢状态;最后,提出整合蛋白质组与代谢组的必要性——蛋白质是表型的直接执行者,代谢组是下游功能产物,两者结合能更全面揭示疾病机制,提升诊断准确性。
现有研究的不足包括:① 多聚焦单一组学(如仅蛋白质或仅代谢物),整合分析较少;② 部分研究样本量小,缺乏BPD对照组,导致诊断特异性不足;③ 未系统结合经典肿瘤标志物,难以直接应用于临床。本研究的创新点在于:① 采用TMT-LC-MS/MS技术规模化筛选NSCLC血浆差异蛋白,结合通路分析定向选择代谢物(氨基酸、胆汁酸);② 纳入110例NSCLC患者、108例BPD患者及100例健康对照的大样本,覆盖筛查(NSCLC vs HC)与鉴别诊断(NSCLC vs BPD)场景;③ 利用逻辑回归、Fisher判别等机器学习算法,整合蛋白、代谢物与经典标志物,建立高性能诊断模型。
3. 研究思路总结与详细解析
本研究的整体框架为:目标——建立基于血浆蛋白、代谢物与经典标志物的NSCLC高特异性、高敏感性筛查及诊断模型;核心科学问题——整合多组学特征能否提升NSCLC诊断准确性;技术路线——“差异蛋白筛选→代谢物定向选择→临床验证→机器学习建模→性能评估”的闭环。
3.1 血浆差异蛋白筛选与通路分析
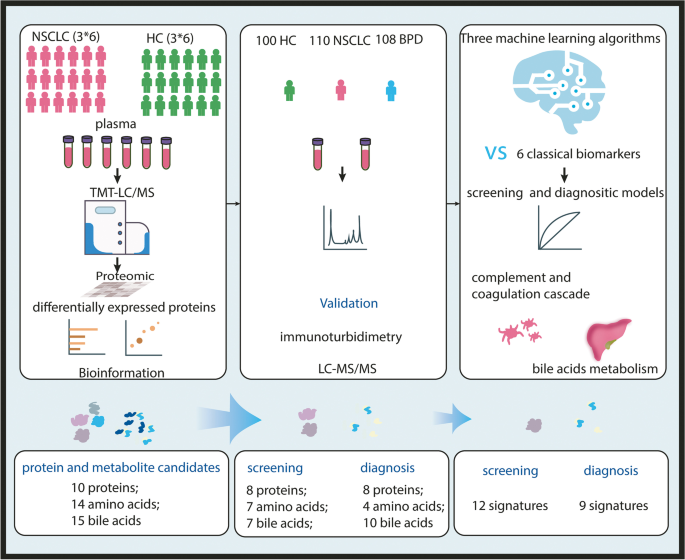
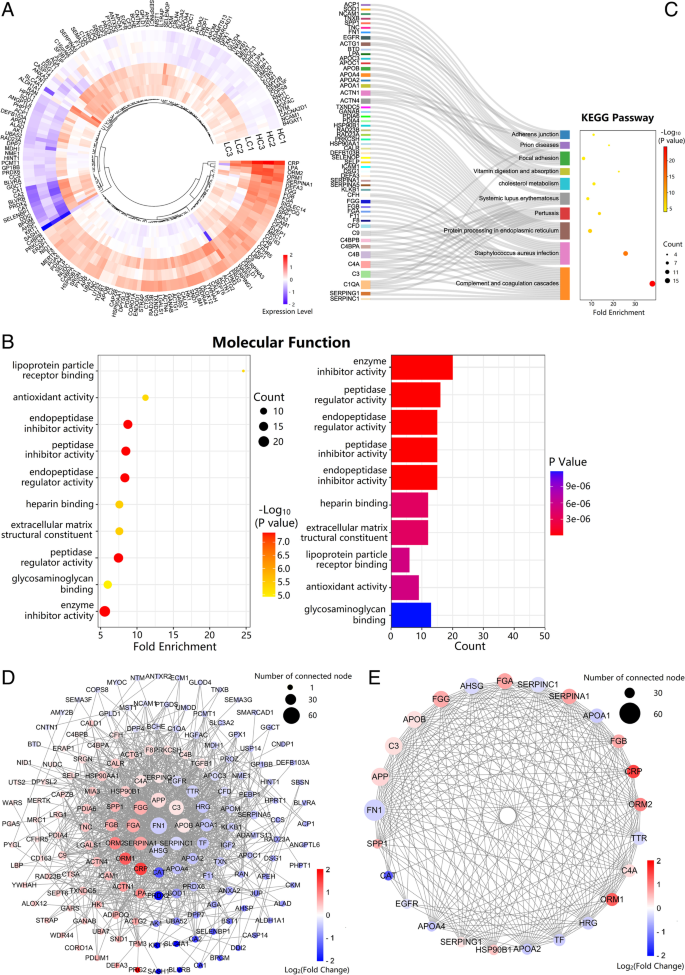
实验目的是通过蛋白质组学技术发现NSCLC患者血浆中的差异表达蛋白(DEPs),并解析其功能通路。方法细节:收集3组混合血浆样本(每组6人,NSCLC组年龄36~78岁,HC组30~75岁,性别匹配),采用TMT-LC-MS/MS技术鉴定蛋白,筛选差异蛋白(fold change>1.2或<0.833,P≤0.05);通过Metascape进行基因本体(GO)与京都基因与基因组百科全书(KEGG)通路分析,利用STRING构建蛋白-蛋白相互作用(PPI)网络,Cytoscape可视化hub基因。
结果解读:共鉴定到942个可定量蛋白,其中180个DEPs(77个上调,103个下调);GO分析显示差异蛋白的分子功能主要富集于“脂蛋白颗粒受体结合”,KEGG通路主要富集于“补体与凝血级联”“胆固醇与胆汁酸代谢”;PPI网络分析筛选出25个hub基因(如ApoA1、ApoB、C3等)。
实验所用关键产品:TMT-LC-MS/MS系统(未提及具体品牌)、Metascape在线工具、STRING数据库、Cytoscape 3.7.2软件。
3.2 候选特征的临床验证
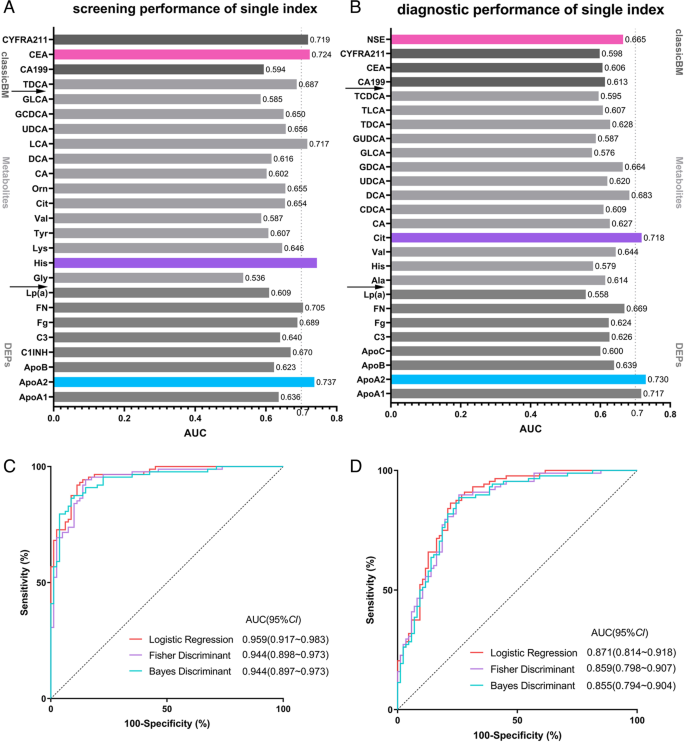
实验目的是验证差异蛋白、代谢物及经典标志物在临床样本中的表达差异。方法细节:纳入110例未接受治疗的NSCLC患者、108例BPD患者(排除肺部肿瘤与胃肠道疾病)及100例HC(无肺部病变及其他器官异常),采集血浆/血清样本(EDTA抗凝血管/凝血管,-80℃保存)。采用浊度抑制免疫测定(H7600生化分析仪、BN™ II特定蛋白分析仪)检测10个DEPs(ApoA1、ApoA2、ApoB、ApoC3、C1INH、C3、C4、纤维蛋白原(Fg)、纤连蛋白(FN)、脂蛋白(a)(Lp(a));采用液相色谱-三重四极杆质谱(LC-20A + API3200MD)检测14种氨基酸(丙氨酸、组氨酸等)与15种胆汁酸(胆酸、脱氧胆酸等);采用电化学发光免疫测定(Cobase801分析仪)检测6种经典肿瘤标志物(CA125、CA199、CEA、CYFRA21-1、NSE、SCC)。
结果解读:与HC组相比,NSCLC组血浆ApoA1、ApoA2、FN水平降低(P<0.05),ApoB、C1INH、C3、C4、Fg水平升高(P<0.05);氨基酸中组氨酸(His)、赖氨酸(Lys)、酪氨酸(Tyr)降低(P<0.05),甘氨酸(Gly)、缬氨酸(Val)、瓜氨酸(Cit)、鸟氨酸(Orn)升高(P<0.05);胆汁酸中脱氧胆酸(DCA)、石胆酸(LCA)等降低(P<0.05),胆酸(CA)、甘氨鹅脱氧胆酸(GCDCA)升高(P<0.05);经典标志物CA199、CEA、CYFRA21-1升高(P<0.05)。与BPD组相比,NSCLC组Fg水平降低(P<0.05),ApoA1、ApoA2、ApoB等升高(P<0.05);氨基酸中丙氨酸(Ala)、His等升高(P<0.05);胆汁酸中牛磺鹅脱氧胆酸(TCDCA)降低(P<0.05),CA、鹅脱氧胆酸(CDCA)等升高(P<0.05);经典标志物CA199、CEA、CYFRA21-1、NSE升高(P<0.05)。
实验所用关键产品:H7600生化分析仪、BN™ II特定蛋白分析仪、CS-5100止血分析仪(检测Fg)、LC-20A液相色谱仪、API3200MD三重四极杆质谱仪、Cobase801电化学发光分析仪。
3.3 机器学习模型建立与性能评估
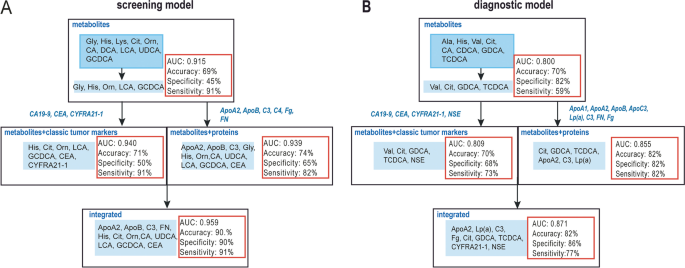
实验目的是利用机器学习算法筛选核心特征,建立NSCLC筛查与诊断模型,并评估其性能。方法细节:将临床验证数据按8:2随机分为训练集(80%)与测试集(20%)。针对筛查场景(NSCLC vs HC),纳入25个差异特征(蛋白、代谢物、经典标志物);针对诊断场景(NSCLC vs BPD),纳入26个差异特征。采用3种监督学习算法:逻辑回归、Fisher判别分析、Bayes判别分析,通过向后逐步elimination法筛选核心特征(移除P>0.05或Wald值<1的变量),利用受试者工作特征曲线(ROC)与约登指数(Youden index)评估模型性能。
结果解读:筛查模型中,逻辑回归算法筛选出12个核心特征(ApoA2、ApoB、C3、FN、His、Cit、Orn、CA、熊脱氧胆酸(UDCA)、LCA、GCDCA、CEA),训练集AUC为0.96,灵敏度92%,特异性89%;测试集准确率90%,灵敏度91%,特异性90%。诊断模型中,逻辑回归算法筛选出9个核心特征(ApoA2、Lp(a)、C3、Fg、Cit、甘氨脱氧胆酸(GDCA)、TCDCA、CYFRA21-1、NSE),训练集AUC为0.871,灵敏度86%,特异性78%;测试集准确率82%,灵敏度77%,特异性86%。与Fisher判别、Bayes判别模型相比,逻辑回归模型性能更优(如筛查模型AUC高于Fisher判别(0.944)与Bayes判别(0.944))。
实验所用关键产品:SPSS 22.0(统计分析)、MedCalc 15.0(ROC分析)、GraphPad Prism 8.4.2(可视化)。
4. Biomarker研究及发现成果解析
Biomarker定位与筛选逻辑
本研究涉及的Biomarker包括3类:① 10个差异蛋白(ApoA1、ApoA2等);② 14种氨基酸(His、Cit等)与15种胆汁酸(CA、LCA等);③ 6种经典肿瘤标志物(CEA、CYFRA21-1等)。筛选与验证逻辑为:TMT-LC-MS/MS发现DEPs→通路分析定向选择代谢物→临床样本(HC、NSCLC、BPD)验证表达差异→机器学习筛选核心特征,形成“发现-验证-优化”的完整链条。
研究过程详述
Biomarker来源为NSCLC患者、BPD患者及HC的血浆/血清样本;验证方法:蛋白用浊度抑制免疫测定(定量),代谢物用液相色谱-三重四极杆质谱(定性+定量),经典标志物用电化学发光免疫测定(定量);特异性与敏感性:筛查模型(NSCLC vs HC)逻辑回归的AUC为0.96(训练集),测试集灵敏度91%,特异性90%;诊断模型(NSCLC vs BPD)AUC为0.871(训练集),测试集灵敏度77%,特异性86%。
核心成果提炼
- 性能优势:整合模型显著优于单一组学模型。例如,筛查场景中,蛋白单组学模型AUC为0.796,代谢物单组学模型AUC为0.915,整合模型AUC提升至0.96;诊断场景中,蛋白单组学模型AUC为0.750,代谢物单组学模型AUC为0.800,整合模型AUC提升至0.871。
- 功能关联:核心Biomarker涉及的通路与NSCLC发生发展密切相关。例如,补体与凝血级联(C3、C4)激活促进肿瘤转移,氨基酸代谢重编程(His降低、Cit升高)支持肿瘤增殖,胆汁酸代谢紊乱(CA升高、LCA降低)参与肿瘤细胞存活。
- 创新性:首次系统整合血浆蛋白、氨基酸、胆汁酸与经典标志物,建立包含BPD组的NSCLC筛查与诊断模型,解决了传统方法难以区分良恶性的问题。
- 统计学验证:所有差异特征均通过P<0.05验证,模型性能通过训练集与测试集的ROC分析确认(如筛查模型测试集AUC 0.96,P<0.05)。
本研究为NSCLC的早期筛查与鉴别诊断提供了高准确性的整合模型,同时揭示了蛋白-代谢物通路在NSCLC中的作用,为后续机制研究与临床转化奠定了基础。