1. 领域背景与文献引入
文献英文标题:Circulating cell-free DNA and machine learning for early cancer detection: current landscape and future perspectives;发表期刊:BMC Medical Genomics;影响因子:5.7(2023年);研究领域:肿瘤液体活检与人工智能辅助早期癌症检测
癌症是全球范围内的主要致死原因,早期检测是提升患者生存率的核心关键。传统组织活检存在侵入性强、难以全面捕捉肿瘤异质性、影响患者生活质量等局限,因此开发非侵入性、能全面获取肿瘤特征的早期检测方法成为领域研究重点。循环游离DNA(cfDNA)作为释放到血液中的短DNA片段,其中肿瘤来源的循环肿瘤DNA(ctDNA)携带肿瘤特异性的遗传与表观遗传改变,为癌症检测提供了重要的分子窗口。
领域共识:cfDNA的研究始于1948年,2010年代后随着下一代测序(NGS)技术的突破,cfDNA检测逐步从基础研究走向临床应用,如非小细胞肺癌(NSCLC)的cfDNA诊断已纳入临床指南。当前领域的研究热点集中在多模态cfDNA标志物融合、人工智能提升低肿瘤负荷样本检测灵敏度、标准化检测流程建立等方向,但仍存在肿瘤异质性导致cfDNA特征差异大、早期肿瘤ctDNA占比低检测难度高、模型可解释性不足、检测成本高昂等未解决的核心问题。本研究旨在系统整合人工智能方法,全面评估cfDNA多维度特征在癌症检测中的优势与局限,为临床转化提供框架性参考。
2. 文献综述解析
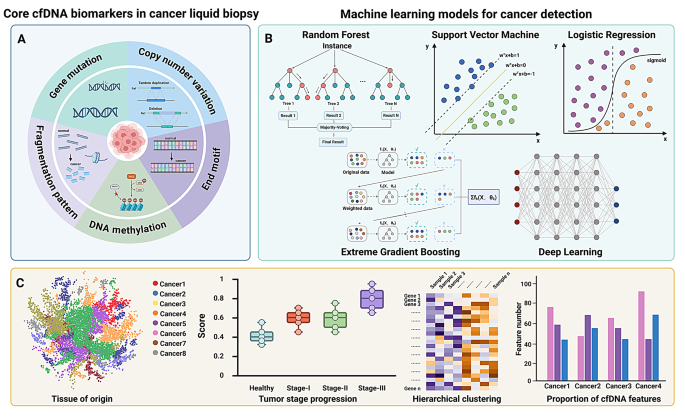
作者对领域内现有研究的分类维度为cfDNA标志物类型(基因突变、拷贝数变异、甲基化、片段化模式、末端基序)与机器学习框架(传统机器学习与深度学习)双维度。
现有研究中,基因突变检测能直接映射致癌通路,提供可解释的临床 actionable 信号,如NSCLC中的EGFR、TP53突变可指导靶向治疗,但早期肿瘤中ctDNA占比极低,检测灵敏度受限,且克隆性造血(CHIP)会引入非肿瘤变异干扰结果;拷贝数变异(CNV)检测可在低测序深度下获取染色体不稳定性信息,适合大规模人群筛查,如超低覆盖度测序结合概率模型能在资源受限场景实现CNV检测,但亚克隆或细微CNV事件的检测难度大,不同分析流程的结果可比性差;DNA甲基化检测在早期肿瘤中灵敏度高,能推断肿瘤组织起源,如结直肠癌(CRC)特异性甲基化标志物的AUC达0.96,但受背景血液细胞组成、队列差异及实验流程批间效应影响;片段化模式与末端基序能从浅层测序中获取染色质组织信息,如子宫内膜癌的片段组学分类器AUC达0.994,但结果重复性受样本预处理、文库制备方法影响。机器学习框架方面,传统模型如随机森林(RF)、极端梯度提升(XGBoost)适合处理小样本、高异质性数据,可解释性强,能快速完成模型训练与部署;深度学习模型如卷积神经网络(CNN)、Transformer能捕捉cfDNA数据中的复杂局部与长程模式,在低肿瘤负荷样本中检测性能更优,但模型复杂度高,可解释性差,对数据量要求高。
本研究的创新价值在于首次系统整合了cfDNA多维度标志物与各类机器学习框架的应用场景,全面对比了不同标志物与模型的优势、局限及互补性,明确了多模态cfDNA特征融合是提升早期癌症检测性能的核心方向,同时系统梳理了领域当前面临的挑战与未来发展路径,为临床转化提供了全面且具有实操性的参考框架,弥补了现有研究中缺乏跨维度整合分析的空白。
3. 研究思路总结与详细解析
整体研究目标是系统综述cfDNA多维度标志物与机器学习结合在早期癌症检测中的应用现状、核心价值、现存局限及未来发展方向;核心科学问题是如何通过多模态cfDNA特征与机器学习的整合,突破早期癌症检测中灵敏度、特异性与可推广性的瓶颈;技术路线遵循“标志物分类解析→机器学习框架应用→多模态融合价值→挑战与前景展望”的逻辑闭环,通过系统文献检索与整合分析,构建完整的领域应用框架。
3.1 cfDNA核心标志物分类与特征解析
实验目的:明确各类cfDNA标志物的生物学基础、检测技术及在癌症检测中的临床价值。
方法细节:通过系统检索PubMed、Web of Science等数据库的相关文献,梳理基因突变、拷贝数变异(CNV)、DNA甲基化、片段化模式、末端基序(EMs)五类cfDNA标志物的定义、检测方法(如NGS、全基因组亚硫酸氢盐测序(WGBS)、低深度全基因组测序(lpWGS)等)及临床应用场景。
结果解读:基因突变能直接反映致癌通路异常,为靶向治疗提供精准依据,如NSCLC中的EGFR、KRAS突变,结直肠癌中的KRAS突变可指导抗EGFR治疗决策;CNV可通过低深度测序检测染色体不稳定性,适合大规模人群筛查,如Li等的研究在CRC患者中检测到1q、8q等区域的扩增及1p、17p等区域的缺失,与肿瘤组织结果一致;DNA甲基化在早期肿瘤中检测灵敏度高,结直肠癌特异性甲基化标志物的AUC达0.96,食管鳞状细胞癌检测灵敏度76.2%、特异性94.1%;片段化模式通过分析片段大小分布与核小体占位区分肿瘤与正常样本,子宫内膜癌检测AUC达0.994;末端基序通过分析cfDNA末端序列偏好富集ctDNA,多癌种检测AUC达0.983,早期肺腺癌检测灵敏度显著提升。
产品关联:文献未提及具体实验产品,领域常规使用下一代测序仪(如Illumina NovaSeq系列)、靶向甲基化检测试剂盒、cfDNA提取试剂盒等。
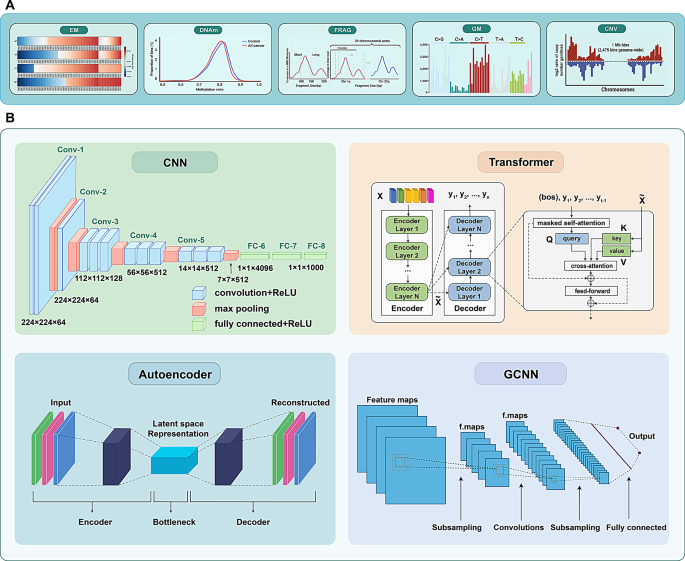
3.2 机器学习框架在cfDNA分析中的应用解析
实验目的:对比传统机器学习与深度学习框架在cfDNA数据处理中的优势、适用场景及临床性能。
方法细节:系统综述卷积神经网络(CNN)、Transformer、自编码器、图卷积神经网络(GCNN)等深度学习模型,以及随机森林(RF)、支持向量机(SVM)、逻辑回归(LR)、XGBoost等传统机器学习模型在cfDNA分析中的应用案例与性能数据。
结果解读:CNN适合捕捉cfDNA数据中的局部染色质模式,在低深度测序数据中检测早期肺癌的灵敏度达70.0%(98%特异性),能从片段化模式与末端基序中挖掘传统特征遗漏的生物学信息;Transformer能捕捉长程基因组依赖关系,DECIDIA模型直接处理原始亚硫酸氢盐片段,结直肠癌检测AUC达0.98,且能跨癌种推广;传统机器学习模型中,RF适合整合多维度异质性cfDNA特征,在肿瘤组织起源推断中灵敏度达92.1%、AUC达0.98;XGBoost在多模态特征融合中表现优异,结直肠癌筛查AUC达0.986;LR模型可解释性强,结直肠癌筛查AUC达0.956,优于血清癌胚抗原(CEA)等传统标志物。
产品关联:文献未提及具体实验产品,领域常规使用Python机器学习库(如Scikit-learn、TensorFlow、PyTorch)、生物信息学分析平台(如Partek Flow)等。
3.3 多模态cfDNA特征融合的临床价值分析
实验目的:探讨多模态cfDNA特征融合在提升癌症检测性能中的核心作用与应用场景。
方法细节:梳理领域内多模态cfDNA特征融合的研究案例,分析基因突变、CNV、甲基化、片段化模式、末端基序等特征融合后的检测性能提升情况。
结果解读:多模态融合能整合不同标志物的互补信息,显著提升早期癌症检测的灵敏度与稳定性,如食管鳞状细胞癌的多模态分析(EMMA)将检测AUC从0.90提升至0.99,同时保持95%以上的特异性;整合甲基化、片段化与CNV特征能实现7种肿瘤类型的组织起源推断,AUC达0.966;结直肠癌的多模态片段组学模型对早期CRC及进展期腺瘤的检测准确性远超单一特征模型。
产品关联:文献未提及具体实验产品,领域常规使用多组学数据整合分析工具(如Cytoscape、R语言相关包)等。
3.4 领域挑战与未来前景分析
实验目的:系统梳理当前cfDNA与机器学习结合在癌症检测中的核心挑战,并提出未来发展方向。
方法细节:从肿瘤异质性、低肿瘤负荷、标准化流程、模型可解释性、检测成本五个维度分析领域现存问题,结合现有研究进展探讨解决方案。
结果解读:肿瘤异质性导致不同癌种、不同阶段的cfDNA特征差异显著,低肿瘤负荷样本中ctDNA占比极低,检测灵敏度受限;缺乏标准化的样本采集、处理与测序流程,批间效应影响结果重复性;深度学习模型的“黑箱”特性限制临床信任与应用;高深度测序与复杂模型的成本高昂,限制大规模人群筛查。未来需推进多模态特征融合、低成本测序策略、可解释人工智能(XAI)、标准化流程建立等方向的研究。
产品关联:文献未提及具体实验产品,领域常规使用标准化cfDNA样本处理试剂盒、低成本测序文库制备试剂盒等。
4. Biomarker研究及发现成果解析
Biomarker定位
本研究涉及五类cfDNA Biomarker,分别为基因突变、拷贝数变异(CNV)、DNA甲基化、片段化模式、末端基序(EMs),筛选与验证逻辑为基于已发表的临床研究数据,从生物学基础、检测方法、诊断性能、优势与局限等维度进行系统验证与分析。
研究过程详述
- 基因突变:来源为肿瘤细胞凋亡、坏死或主动分泌释放的ctDNA,检测方法为NGS、数字PCR,能直接反映致癌通路异常,如NSCLC中的EGFR突变可指导靶向治疗,但早期肿瘤中ctDNA占比极低,检测灵敏度受限,需超深度测序或机器学习辅助错误抑制提升性能。
- CNV:来源为肿瘤细胞的染色体不稳定性,检测方法为低深度全基因组测序(lpWGS)、超低覆盖度测序结合概率模型,能在低测序深度下获取基因组剂量信息,适合大规模人群筛查,如Hallermayr等的ML分类器整合CNV与其他特征,CRC检测灵敏度高,但亚克隆CNV事件检测难度大,不同分析流程结果可比性差。
- DNA甲基化:来源为肿瘤细胞的表观遗传改变,检测方法为全基因组亚硫酸氢盐测序(WGBS)、靶向甲基化panel,早期肿瘤中灵敏度高,结直肠癌检测AUC达0.96(文献未明确样本量),食管鳞状细胞癌检测灵敏度76.2%、特异性94.1%(文献未明确样本量),但受背景血液细胞组成、队列差异影响。
- 片段化模式:来源为肿瘤细胞凋亡时的核酸酶切割偏好,检测方法为低深度全基因组测序,分析片段大小分布与核小体占位,子宫内膜癌检测AUC达0.994、灵敏度97.8%(文献未明确样本量),但结果重复性受样本预处理、文库制备方法影响。
- 末端基序(EMs):来源为肿瘤细胞核酸酶切割的末端序列偏好,检测方法为NGS分析cfDNA末端k-mer序列,能富集低占比ctDNA,多癌种检测AUC达0.983、灵敏度95.5%、特异性95.0%(文献未明确样本量),但受文库制备、序列平台 artifacts 影响。
核心成果提炼
这五类cfDNA Biomarker各有互补优势,基因突变提供可解释的致癌通路信息,CNV适合大规模筛查,甲基化在早期肿瘤中灵敏度高,片段化模式与末端基序能从浅层测序中获取染色质信息。多模态融合能显著提升早期癌症检测性能,如食管鳞状细胞癌的多模态分析将AUC从0.90提升至0.99,同时实现更可靠的肿瘤组织起源推断。本研究的创新性在于首次系统整合了cfDNA多维度标志物与机器学习框架的应用场景,明确了多模态融合是突破领域瓶颈的核心方向,为临床转化提供了全面的参考框架。