1. 领域背景与文献引入
文献英文标题:Trans-omics analyses identify the biochemical network of LPCAT1 associated with coronary artery disease;发表期刊:Biomarker Research;影响因子:未公开;研究领域:心血管疾病(冠状动脉疾病)多组学与生物标志物研究
冠状动脉疾病(CAD)是全球范围内导致死亡的首要原因,尤其是在发达国家中负担更为沉重。领域共识:过去十年中,全基因组关联研究(GWAS)已识别出超过300个与CAD相关的染色体位点,但超过90%的常见风险变异位于蛋白编码区之外,仅能解释约25%的疾病遗传度,且这些关联缺乏明确的机制解析,难以转化为临床应用。当前研究热点聚焦于多组学整合分析,通过结合基因组、代谢组、转录组等多层数据,解析疾病的分子调控网络,寻找具有临床价值的生物标志物与治疗靶点。然而,现有研究仍存在不足:一方面,多数多组学研究针对欧洲人群,缺乏东亚人群的特异性数据;另一方面,较少研究将基因组变异与代谢组表型直接关联,并通过机器学习构建精准的CAD预测模型。针对这一空白,本研究整合全基因组SNP分析与靶向代谢组学数据,结合机器学习技术,旨在揭示CAD的分子调控网络,识别潜在的生物标志物与风险基因,为CAD的早期诊断与风险分层提供新的策略。
2. 文献综述解析
作者的综述逻辑以CAD的研究现状为起点,先阐述GWAS在CAD研究中的贡献与局限,进而引出多组学整合分析的必要性,最后聚焦于代谢组作为连接基因组与临床表型的中间层的重要性。
现有研究中,GWAS已系统识别出大量与CAD相关的遗传位点,但这些位点大多位于非编码区,功能机制不明确,且单个位点的效应量较小,难以直接应用于临床。代谢组学研究则发现,血浆代谢物(尤其是磷脂类)的变化与CAD的发生发展密切相关,可作为疾病的早期生物标志物,但现有研究多单独分析代谢组或基因组数据,缺乏两者的整合关联分析。在多组学整合方法上,主要分为两类:一类是无偏的网络整合方法,通过高维数据构建分子网络,识别与CAD因果相关的通路;另一类是靶向特定遗传通路,关联下游组学数据。两类方法各有优势:无偏方法能发现新的调控通路,但计算复杂度高;靶向方法更聚焦,但可能遗漏未知机制。
本研究的创新价值在于,首次针对东亚人群(台湾队列),整合全基因组SNP与靶向代谢组学数据,通过K聚类分析与机器学习技术,构建了CAD的跨组学预测模型,并明确了LPCAT1基因单倍型通过调控磷脂代谢影响CAD发生的机制。与现有研究相比,本研究不仅填补了东亚人群多组学CAD研究的空白,还将遗传变异与代谢表型直接关联,为CAD的精准风险评估提供了新的生物标志物与模型。
3. 研究思路总结与详细解析
本研究的整体框架为:以“遗传变异-代谢表型-临床疾病”的调控轴为核心,通过队列研究整合全基因组SNP与靶向代谢组学数据,结合K聚类分析识别CAD相关的分子亚型,进而通过跨组学关联分析明确LPCAT1基因单倍型与CAD的关联,最终利用机器学习构建CAD的精准预测模型并验证其效能。研究目标是揭示CAD的分子调控网络,识别潜在的生物标志物与风险基因;核心科学问题是LPCAT1的遗传变异如何通过调控磷脂代谢通路影响CAD的发生发展;技术路线遵循“队列构建-组学检测-聚类分析-关联验证-模型构建”的闭环逻辑。
3.1 研究队列构建与临床特征分析
实验目的是建立具有代表性的CAD研究队列,明确对照组、高危组与CAD组之间的临床特征差异,为后续组学分析提供基础。方法细节为:从2013年8月至2020年11月的台湾东北社区医学研究队列中招募781名参与者,按照临床标准分为对照组(n=271,无重大系统性疾病)、高危组(n=363,10年动脉粥样硬化性心血管疾病风险≥20%)与CAD组(n=147,经血管造影证实冠状动脉狭窄≥75%或有相关病史),收集所有参与者的临床数据、病史信息与生物样本,进行全面的临床评估。结果解读:CAD组的男性比例更高,年龄、体重指数(BMI)、腰围、血压等指标显著高于对照组,合并糖尿病、慢性肾病的比例也更高;血脂指标中,CAD组的总胆固醇、高密度脂蛋白(HDL)、低密度脂蛋白(LDL)水平显著低于其他两组,而甘油三酯(TG)、高敏C反应蛋白水平显著升高(n=781,P<0.05),提示临床特征的差异与CAD的发生发展密切相关。
产品关联:文献未提及具体实验产品,领域常规使用临床生化检测试剂盒、电子病历系统、血管造影设备等。
3.2 靶向代谢组学检测与分析
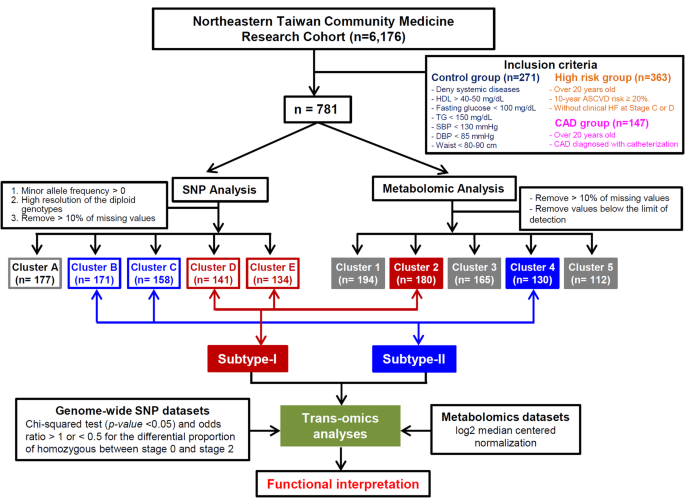
实验目的是检测三组参与者的血浆代谢物水平,识别与CAD相关的代谢标志物,尤其是磷脂类代谢物的变化。方法细节为:采用EDTA管收集空腹血浆样本,离心分离后于-80℃保存,使用AbsoluteIDQ p180试剂盒(BIOCRATES Life Sciences AG,奥地利)进行靶向代谢组学检测,通过液相色谱-串联质谱(LC-MS/MS)定量检测21种氨基酸、9种生物胺、15种酰基肉碱、84种磷脂与14种鞘脂,共143种代谢物,使用MetIQ软件进行数据处理与归一化。结果解读:代谢组学分析显示,血浆磷脂水平从对照组到高危组再到CAD组逐渐降低,提示磷脂代谢紊乱与CAD的进展密切相关;通过K聚类分析,将所有参与者分为5个代谢亚型,其中亚型4的CAD患病率最高(40%),BMI、TG水平最高,而HDL水平最低;亚型2则为最健康的亚型,CAD患病率最低,血脂指标最优(n=781,P<0.05)。
产品关联:实验所用关键产品:AbsoluteIDQ p180试剂盒(BIOCRATES Life Sciences AG,奥地利)、TQS质谱仪(Waters Corp.,美国)、MetIQ软件(Biocrates Life Science AG,奥地利)。
3.3 全基因组SNP分析与筛选
实验目的是识别与CAD相关的遗传变异,尤其是与磷脂代谢相关的基因位点。方法细节为:从白细胞中提取基因组DNA,使用Axiom™ Genome-Wide TWB 2.0芯片进行全基因组SNP检测,经过质量控制(次要等位基因频率<0.01、偏离哈迪-温伯格平衡P<1×10⁻⁶、缺失率>10%的SNP被过滤),最终保留370,394个SNP进行后续分析;使用卡方检验与SAIGE方法分析SNP与CAD的关联,结合Bonferroni校正进行多重检验校正。结果解读:全基因组关联分析显示,195个SNP与CAD的关联达到P<1×10⁻²,其中LPCAT1基因的多个SNP位点具有较高的统计学显著性;通过机器学习筛选出10个与CAD最相关的SNP,其中LPCAT1基因的SNP位列其中;将SNP进行K聚类分析,分为5个遗传亚型,其中亚型B的CAD患病率最高(47.4%),与代谢亚型4显著关联(n=781,P<0.05)。
产品关联:实验所用关键产品:Axiom™ Genome-Wide TWB 2.0芯片(Thermo Fisher Scientific,美国)、PLINK软件、SAIGE分析工具。
3.4 多组学聚类与关联分析
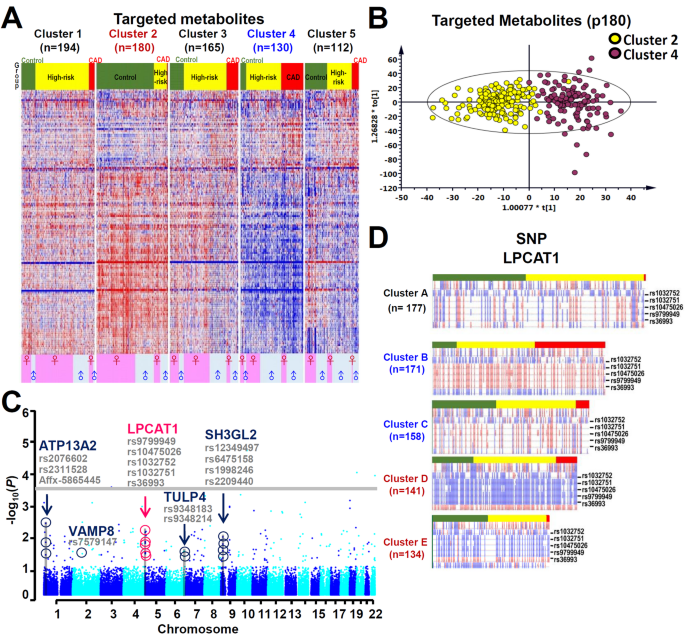
实验目的是整合代谢组与基因组数据,识别与CAD相关的跨组学关联,尤其是LPCAT1基因与磷脂代谢的关联。方法细节为:将代谢亚型与遗传亚型进行关联分析,采用卡方检验验证关联的统计学显著性;针对LPCAT1基因的5个SNP(rs1032752、rs1032751、rs10475026、rs9799949、rs36993)进行单倍型分析,识别与CAD相关的单倍型;采用正交偏最小二乘判别分析(OPLS-DA)分析不同LPCAT1单倍型对应的代谢组差异。结果解读:代谢亚型2与遗传亚型D、E显著关联,代谢亚型4与遗传亚型B、C显著关联(P=2.5×10⁻¹⁹与P=1.13×10⁻¹³);LPCAT1单倍型3(由5个SNP的变异等位基因组成)在CAD组中的频率为27.21%,显著高于对照组的13.33%(n=781,P=0.02);OPLS-DA分析显示,不同LPCAT1单倍型对应的代谢组模式存在显著差异,尤其是磷脂类代谢物的水平(n=151,R²=0.814,Q²=0.755)。
产品关联:文献未提及具体实验产品,领域常规使用SIMCA-P软件(Umetrics,瑞典)进行OPLS-DA分析。
3.5 机器学习辅助CAD预测模型构建
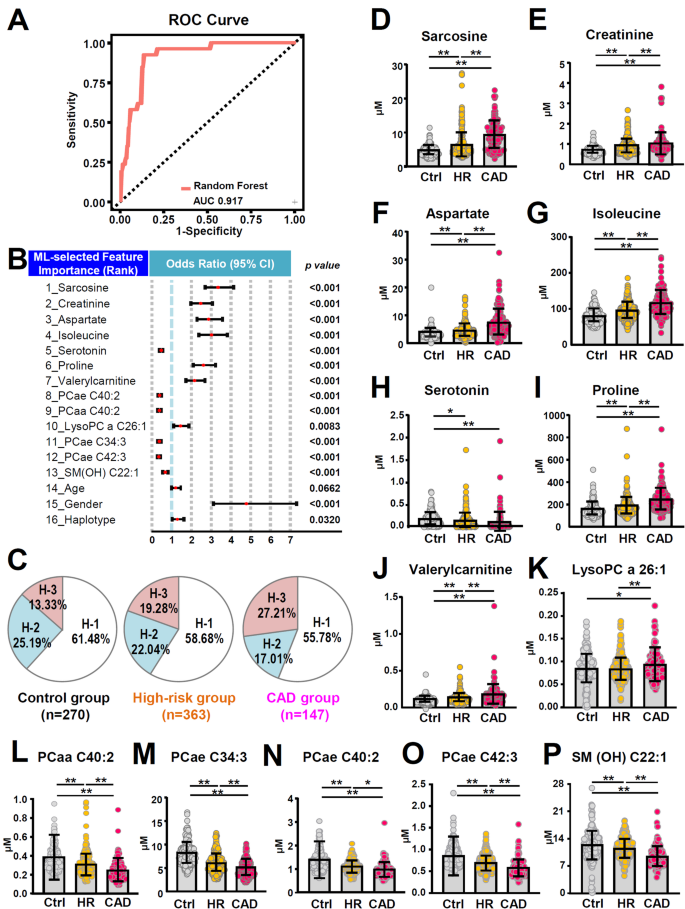
实验目的是整合临床特征、代谢组与基因组数据,构建CAD的精准预测模型,验证模型的效能。方法细节为:将数据集按照8:2的比例分为训练集与验证集,采用四种机器学习算法(随机森林RF、支持向量机SVM、LASSO、极端梯度提升XGBoost)进行模型训练,通过100次 bootstrap重复进行特征选择,最终筛选出16个最具预测价值的特征(包括LPCAT1单倍型、代谢物与临床特征),构建整合模型并验证其效能。结果解读:随机森林模型的效能最优,在验证集中的受试者工作特征曲线下面积(AUC)为0.917,准确率为0.805;LPCAT1单倍型是模型中的重要预测特征之一;针对高危组与CAD组的区分,模型的AUC为0.880,准确率为0.740,提示模型具有良好的风险分层能力;与现有CAD风险评估工具相比,本模型的效能更优(n=781,P<0.05)。
产品关联:实验所用关键产品:R软件(版本3.6.3)及相关包(randomForest、e1071、glmnet、xgboost、caret、pROC等)。
3.6 LPCAT1单倍型与磷脂代谢关联分析
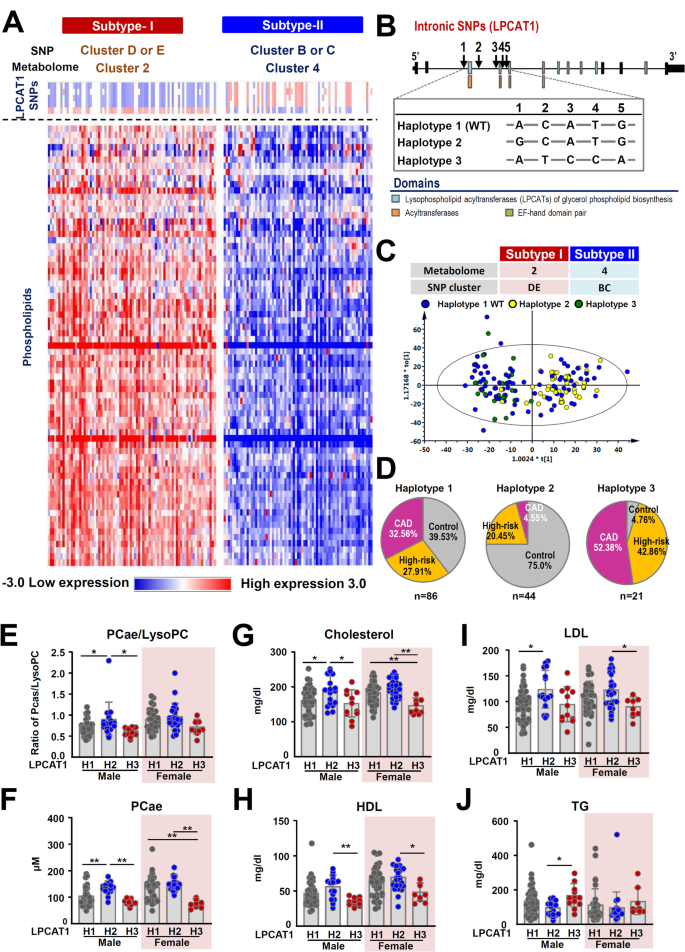
实验目的是探讨LPCAT1单倍型影响CAD的机制,明确其对磷脂代谢的调控作用。方法细节为:分析不同LPCAT1单倍型对应的磷脂代谢物水平,尤其是磷脂酰胆碱(PC)与溶血磷脂酰胆碱(LysoPC)的比例;进行性别特异性分析,明确LPCAT1单倍型对不同性别血脂指标的影响;结合现有文献,探讨LPCAT1在磷脂代谢中的作用机制。结果解读:携带LPCAT1单倍型3的参与者,其血浆PCae/LysoPC比例显著降低,PCae水平显著降低,而TG水平显著升高(n=781,P<0.05);性别特异性分析显示,男性携带单倍型3时,PCae/LysoPC比例、PCae水平、总胆固醇、HDL水平显著低于单倍型2,TG水平显著升高;女性携带单倍型3时,PCae水平、总胆固醇、HDL、LDL水平显著低于单倍型2(n=781,P<0.05);机制上,LPCAT1通过Land循环将LysoPC转化为PC,单倍型3可能导致LPCAT1酶活性降低,进而导致PC合成减少,LysoPC积累,促进动脉粥样硬化的发生。
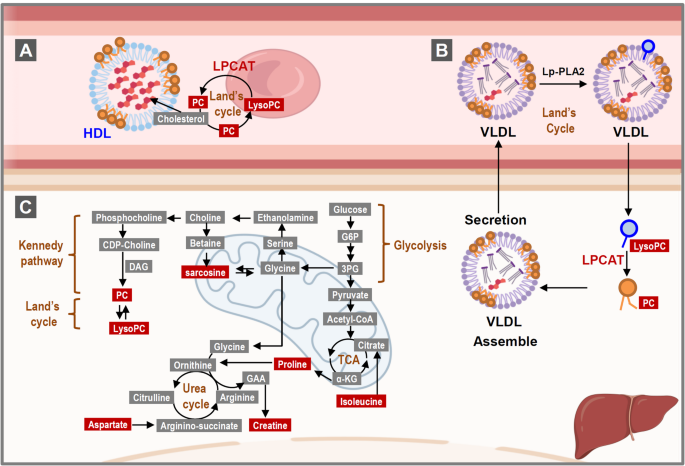
产品关联:文献未提及具体实验产品,领域常规使用代谢组学检测试剂盒、生物信息学分析工具进行机制探讨。
4. Biomarker研究及发现成果
Biomarker定位
本研究识别的Biomarker分为两类:一类是血浆磷脂类代谢物(包括PCae C34:3、PCae C40:2、PCae C42:3、LysoPCa C26:1等),另一类是LPCAT1单倍型3。筛选与验证逻辑为:首先通过代谢组学分析发现血浆磷脂水平随CAD进展逐渐降低,初步确定其为潜在生物标志物;然后通过全基因组SNP分析找到与磷脂代谢相关的LPCAT1基因,结合单倍型分析识别出与CAD相关的单倍型3;进而通过跨组学关联分析验证LPCAT1单倍型3与磷脂代谢的关联;最后通过机器学习将这些Biomarker纳入CAD预测模型,验证其诊断效能。
研究过程详述
血浆磷脂类代谢物的来源为参与者的空腹血浆样本,采用AbsoluteIDQ p180试剂盒进行靶向定量检测,验证方法包括组间差异分析(ANOVA)、OPLS-DA分析与机器学习特征选择,其特异性与敏感性表现为:在CAD预测模型中,这些代谢物的AUC为0.917,敏感性与特异性未明确给出,但模型的整体准确率为0.805;LPCAT1单倍型3的来源为全基因组SNP检测数据,通过单倍型分析识别,验证方法包括卡方检验、单倍型频率分析与跨组学关联分析,其与CAD的关联表现为:CAD组中携带单倍型3的比例为27.21%,显著高于对照组的13.33%(n=781,P=0.02),风险比(OR)未明确给出,但在机器学习模型中为重要的预测特征。
核心成果提炼
本研究的核心成果包括:1. 血浆磷脂类代谢物水平随CAD进展逐渐降低,可作为CAD进展的生物标志物,其水平变化与疾病严重程度相关(n=781,P<0.05);2. LPCAT1单倍型3是CAD的遗传风险因素,携带该单倍型的参与者CAD发病风险显著升高,且通过调控磷脂代谢(降低PC合成、升高LysoPC水平)促进疾病发生;3. 整合临床特征、代谢组与基因组数据的机器学习预测模型,AUC达到0.917,具有良好的CAD诊断与风险分层效能,LPCAT1单倍型3是模型中的关键特征之一;4. 首次在东亚人群中揭示了LPCAT1基因通过调控磷脂代谢通路影响CAD发生的机制,为CAD的精准诊断与治疗提供了新的靶点。