1. 领域背景与文献引入
文献英文标题:Proteome-wide evidence for enhanced positive Darwinian selection within intrinsically disordered regions in proteins;发表期刊:Genome Biology;影响因子:未公开;研究领域:蛋白质组学与进化生物学(蛋白质结构与适应性进化方向)
进化生物学中,适应性进化的分子机制是核心研究问题之一,随着基因组测序技术的突破,比较基因组学成为检测物种内及物种间选择事件的关键手段。中性进化理论认为多数突变呈中性或有害,但近年研究证实正选择在基因进化中发挥重要作用,尤其是在生物应对环境变化的适应性过程中。蛋白质结构分为有序结构区域(如α螺旋、β折叠)和内在无序区(intrinsically disordered region, IDR),其中IDR在真核生物中含量丰富,约50%至60%的酿酒酵母蛋白质包含至少一段长度超过30个氨基酸的IDR,且IDR参与信号传导、转录调控等多种关键生物学功能。然而,此前缺乏全蛋白质组水平的系统研究,明确IDR与适应性正选择的关联,这一空白限制了对蛋白质可进化性分子基础的理解。本文通过分析64株酵母菌株的单核苷酸多态性(SNP)数据,系统比较不同蛋白质结构区域的选择压力,填补了这一研究空白,为揭示IDR在适应性进化中的核心作用提供了直接证据。
2. 文献综述解析
作者的综述逻辑以“适应性进化的分子基础→蛋白质结构与进化的关联→IDR研究现状”为脉络,先介绍适应性进化的研究意义及检测方法,再聚焦蛋白质结构的进化动力学,最后引出IDR的研究缺口。现有研究方面,比较基因组学方法已成功应用于检测正选择作用的基因,但多数研究聚焦于整个基因或有序结构域,对IDR的选择压力分析较为零散;已知IDR在真核生物中广泛存在,且参与多种动态生物学过程,但关于其进化模式的研究较少,未明确IDR与正选择的直接关联。现有研究的局限性在于缺乏全蛋白质组水平的系统分析,无法从整体层面揭示IDR在适应性进化中的特殊角色。本文的创新点在于首次结合系统发育和群体遗传学方法,在全蛋白质组水平证明IDR中的正选择信号显著高于有序结构区域,且高IDR含量的蛋白质类别(如转录因子)正选择位点显著富集,为IDR作为适应性进化的关键区域提供了直接证据,拓展了对蛋白质可进化性机制的认知。
3. 研究思路总结与详细解析
本研究的核心目标是明确蛋白质不同结构区域(有序区、内在无序区)的正选择压力差异,核心科学问题是内在无序区是否在生物适应性进化中承担特殊的可进化性角色,技术路线遵循“数据获取→结构预测→选择压力检测→功能验证→关联分析”的闭环逻辑,通过多层面实验验证内在无序区与正选择的关联。
3.1 数据收集与基因比对构建
实验目的是获取可靠的基因序列比对数据集,为后续选择压力分析提供基础。方法细节上,研究收集了64株酿酒酵母(Saccharomyces cerevisiae)和假丝酵母(Saccharomyces paradoxus)的菌株特异性SNP数据,针对3746个基因构建多序列比对,使用DIALIGN-T进行翻译辅助比对以避免移码突变,过滤掉序列一致性低于70%的比对结果,并通过GENECONV方法去除存在重组事件的比对。结果解读显示,最终得到的3746个高质量基因比对,确保了后续选择压力分析的可靠性。文献未提及具体实验产品,领域常规使用序列分析软件(如DIALIGN-T、GENECONV)及公开基因组数据库资源。
3.2 蛋白质结构区域预测
实验目的是精准区分蛋白质中的有序结构区域(α螺旋、β折叠)和内在无序区。方法细节上,使用PSIPRED软件预测α螺旋和β折叠结构(置信阈值设为8),使用VSL2软件预测内在无序区(置信阈值设为0.8),并去除结构预测重叠的氨基酸残基。结果解读显示,预测得到酿酒酵母蛋白质中α螺旋、β折叠、内在无序区的平均残基占比分别为26%、6%、23%,为后续结构区域与选择压力的关联分析提供了明确的分类基础。文献未提及具体实验产品,领域常规使用蛋白质结构预测软件(如PSIPRED、VSL2)。
3.3 基于固定效应似然法的密码子位点选择压力分析
实验目的是检测单个密码子位点的正选择和负选择信号,比较不同结构区域的选择压力差异。方法细节上,使用HyPhy软件中的固定效应似然(Fixed Effects Likelihood, FEL)方法,对3746个基因比对进行分析,计算同义替换率(α)和非同义替换率(β),以β>α作为正选择的判断标准,α>β作为负选择的判断标准,采用P≤0.1作为显著性阈值。结果解读显示,共检测到7561个正选择位点和178408个负选择位点;内在无序区中正选择与负选择位点的比值是有序结构区域的3倍,且内在无序区中正选择位点的比例比有序结构区域高近3倍(n=3746,P≤0.001);长度≥30个氨基酸的长内在无序区中,正选择信号显著强于三级结构域(图2c)。随机化验证结果显示,内在无序区中的正选择位点显著富集(P≤0.001),而负选择位点的分布与有序结构区域无显著差异;此外,528个基因中内在无序区含量与正选择位点数量呈显著正相关(n=528,P≤0.05),仅28个基因呈负相关。
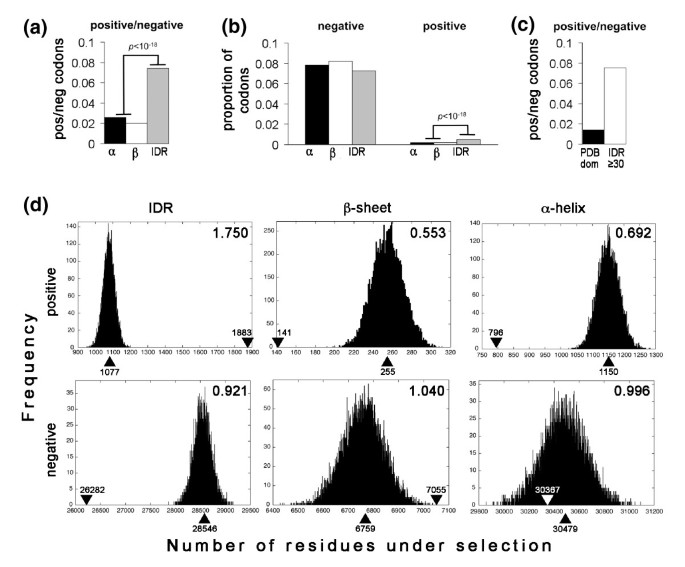
文献未提及具体实验产品,领域常规使用进化分析软件(如HyPhy)。
3.4 基于McDonald-Kreitman检验的基因水平选择压力分析
实验目的是从基因整体水平验证内在无序区与正选择的关联。方法细节上,使用McDonald-Kreitman检验计算固定指数(Fixation Index, FI),FI定义为(dN/dS)/(pN/pS),其中dN/dS为物种间非同义与同义替换率的比值,pN/pS为物种内非同义与同义多态性的比值,FI>1表示正选择作用,FI<1表示负选择作用,分析FI与内在无序区含量、有序结构含量的相关性。结果解读显示,FI与内在无序区含量呈显著正相关(相关系数r_s=0.28,n=3746,P≤10^-18),与有序结构含量呈显著负相关(相关系数r_s=-0.26,n=3746,P≤10^-18)(图3a、b);而基因的GC含量与FI、内在无序区含量均无显著相关性(图3c、d)。将基因按FI高低分为两组后,高FI组的内在无序区含量显著高于低FI组(P≤10^-15);对 concatenated的结构区域进行分析显示,内在无序区的FI接近1.0,有序结构区域的FI低于1.0,进一步验证了内在无序区的正选择富集。
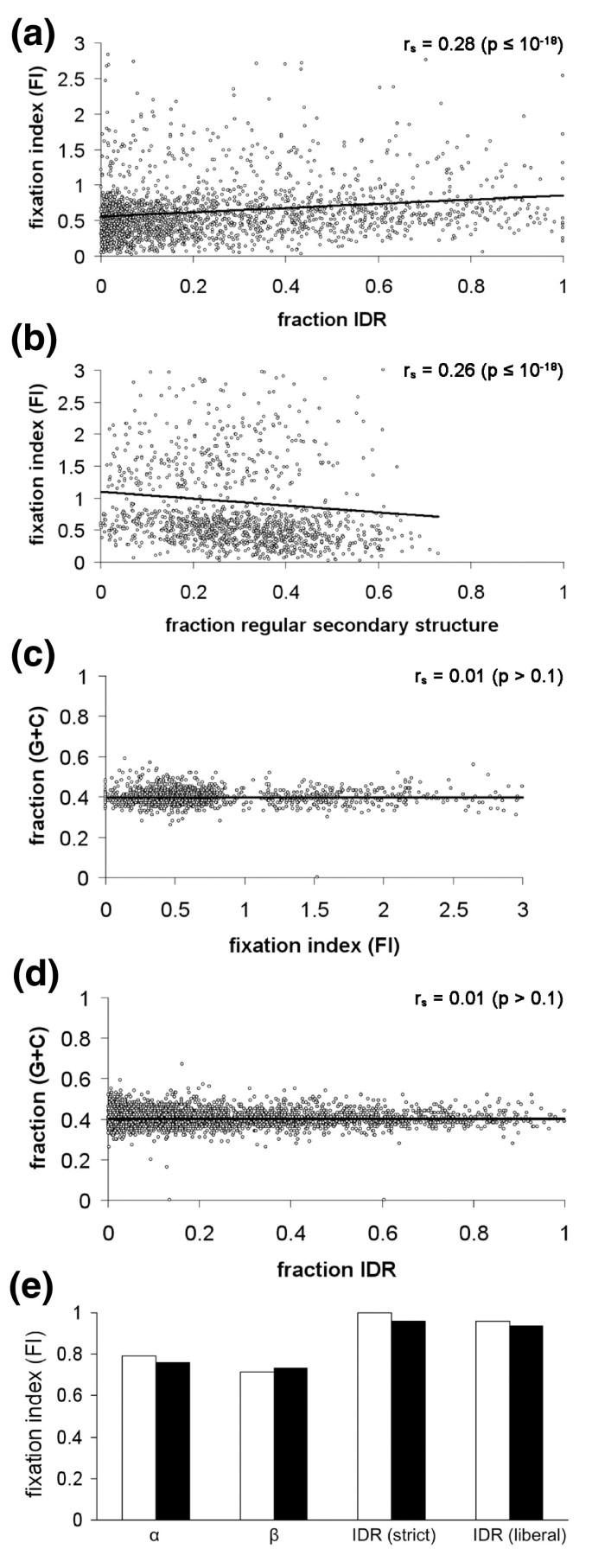
文献未提及具体实验产品,领域常规使用群体遗传学分析软件(如libsequence中的MKtest)。
3.5 功能位点分布验证
实验目的是排除内在无序区中正选择富集是由于功能位点密度低的可能性。方法细节上,使用Limacs方法预测Pfam结构域中的功能位点,计算Limacs功能位点指数,即(内在无序区中功能位点/内在无序区中非功能位点)/(非内在无序区中功能位点/非内在无序区中非功能位点),分析内在无序区与非内在无序区的功能位点分布差异。结果解读显示,Limacs功能位点指数接近或大于1.0,表明内在无序区中的功能位点密度不低于非内在无序区,且随着内在无序区预测阈值的提高,该指数进一步升高,说明内在无序区中的正选择富集并非因为功能位点少,而是真实的适应性进化信号(图4)。
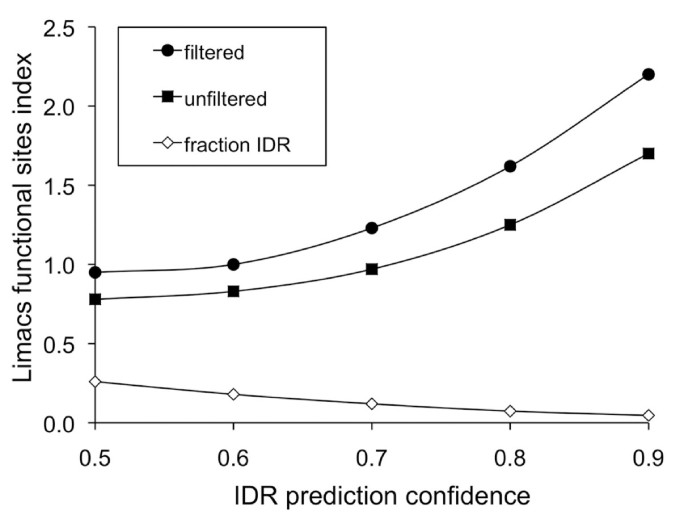
文献未提及具体实验产品,领域常规使用功能位点预测软件(如Limacs)及Pfam数据库。
3.6 蛋白功能类别与选择压力、内在无序区含量的关联分析
实验目的是分析不同功能类别蛋白质的选择压力与内在无序区含量的关系。方法细节上,使用慕尼黑蛋白质序列信息中心(MIPS)的FunCat和ProteinCat注释系统将基因分类,通过随机化检验检测不同类别中选择位点的富集情况,分析类别平均内在无序区含量与选择压力的相关性。结果解读显示,FunCat分类中,细胞生长、形态发生、信号传导、核酸生物学等类别正选择位点显著富集(P≤0.01),而代谢、蛋白折叠等类别负选择位点富集;ProteinCat分类中,转录因子类别正选择位点显著富集,酶类类别负选择位点富集(图5)。进一步分析显示,正选择富集的类别平均内在无序区含量显著高于负选择富集的类别,转录因子类别位于内在无序区含量排名的顶端(图6),说明高内在无序区含量的蛋白质类别更易受到正选择作用。
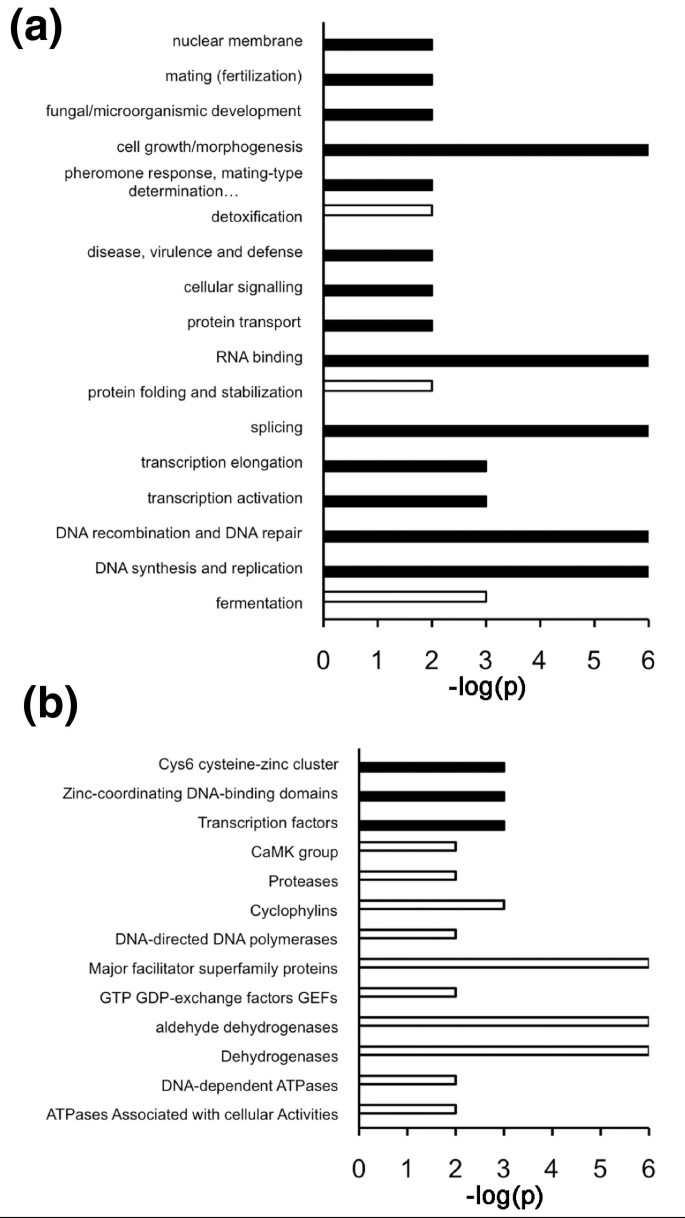
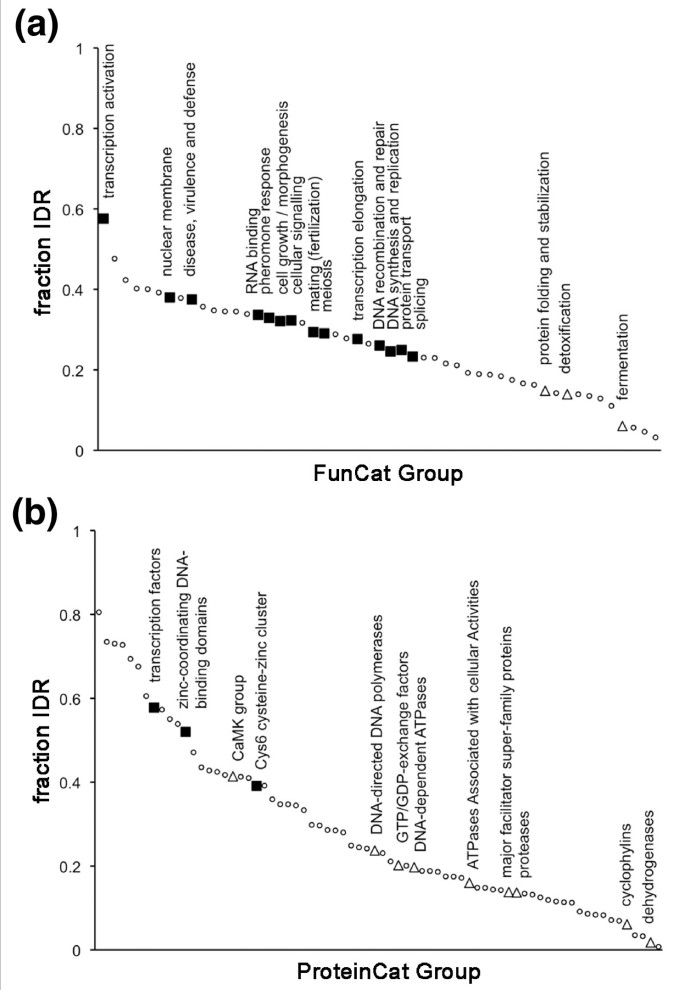
文献未提及具体实验产品,领域常规使用功能注释数据库(如MIPS FunCat、ProteinCat)。
4. Biomarker研究及发现成果解析
Biomarker定位
本文的核心Biomarker为蛋白质内在无序区(IDR),其筛选逻辑是先通过VSL2结构预测软件从酿酒酵母蛋白质序列中识别内在无序区,再通过密码子位点、基因整体、功能类别三个层面的选择压力分析,验证其与正选择的关联;验证逻辑遵循“位点水平→基因水平→系统水平”的递进式验证,确保结论的可靠性。
研究过程详述
内在无序区来源于酿酒酵母的蛋白质序列,通过VSL2软件预测(置信阈值0.8),验证方法包括固定效应似然法检测密码子位点选择压力、McDonald-Kreitman检验分析基因水平选择压力、Limacs方法分析功能位点分布、功能类别关联分析。特异性方面,内在无序区中的正选择位点比例是有序结构区域的近3倍(n=3746,P≤0.001);敏感性方面,528个基因中内在无序区含量与正选择位点数量呈显著正相关(n=528,P≤0.05)。
核心成果提炼
内在无序区作为适应性进化的关键区域,其正选择信号显著高于有序结构区域,且高内在无序区含量的蛋白质类别(如转录因子)正选择位点显著富集,提示内在无序区在产生和维持具有适应潜力的遗传变异中起重要作用,是生物可进化性的核心决定因素之一。统计结果显示,固定指数(FI)与内在无序区含量的相关系数r_s=0.28(n=3746,P≤10^-18),高FI组的内在无序区含量显著高于低FI组(P≤10^-15),为内在无序区的进化意义提供了坚实的统计学支持。这一发现为理解生物应对环境变化的适应性机制提供了新视角,也为蛋白质工程中设计具有高可进化性的蛋白区域提供了理论依据。