1. 领域背景与文献引入
文献英文标题:SAKURA: a knowledge-guided dimensionality reduction framework for single-cell transcriptomic data;发表期刊:Genome Biology;影响因子:未公开;研究领域:单细胞转录组学、生物信息学。
单细胞转录组技术的快速发展为解析细胞异质性提供了高分辨率工具,但高维数据的冗余性和噪声也给后续分析带来挑战,降维成为单细胞转录组数据分析的核心步骤之一。领域共识:现有降维方法主要分为无监督和半监督两类,无监督方法(如PCA、NMF、DCA等)无需外部知识,能保留数据中的主要信号,但往往会丢失稀有细胞亚群或高度相似细胞亚群的关键生物信息;半监督方法(如MCML、scNym)可利用标注细胞提升特定细胞的聚类效果,但需要大量人工标注的细胞样本,获取过程耗时且成本高,部分方法还存在内存消耗过大的问题。当前领域未解决的核心问题是:如何在降维过程中有效保留稀有但具有重要生物学意义的信号,同时避免对全局数据结构的过度扭曲,且无需依赖难以获取的标注细胞样本。SAKURA框架的研究初衷正是针对这一核心问题,提出以基因列表作为知识输入的引导式降维策略,填补现有方法在平衡全局数据保留与稀有信号挖掘之间的空白。
2. 文献综述解析
作者对现有单细胞转录组降维研究的分类维度为无监督降维方法和半监督降维方法两类。无监督降维方法的核心优势在于无需外部知识输入,适合探索性数据分析,能快速捕捉数据中的主要结构特征;但这类方法的局限性也十分明显,其优先保留全局占比更高的细胞信号,会不可避免地丢失稀有细胞亚群、高度相似细胞亚群的关键信息,导致后续聚类分析无法有效区分这些具有重要生物学功能的细胞类群。半监督降维方法的优势在于可利用已有的细胞标注信息,针对性地提升特定细胞类群的聚类精度;但局限性在于需要大量经过人工验证的标注细胞样本,获取过程依赖专业知识且耗时费力,部分方法(如netAE)还存在内存消耗过大的问题,难以应用于大规模单细胞数据集。
SAKURA的创新价值通过与现有研究的对比凸显:与无监督方法相比,SAKURA通过引入基因列表作为知识输入,能在降维过程中主动强化目标基因相关的信号,有效保留稀有细胞亚群和相似亚群的信息,同时通过正则化机制避免对全局数据结构的过度扭曲;与半监督方法相比,SAKURA无需依赖标注细胞样本,仅需领域内已知的基因列表即可实现引导式降维,大幅降低了外部知识的获取成本,且性能更稳定,不受标注样本数量的限制。
3. 研究思路总结与详细解析
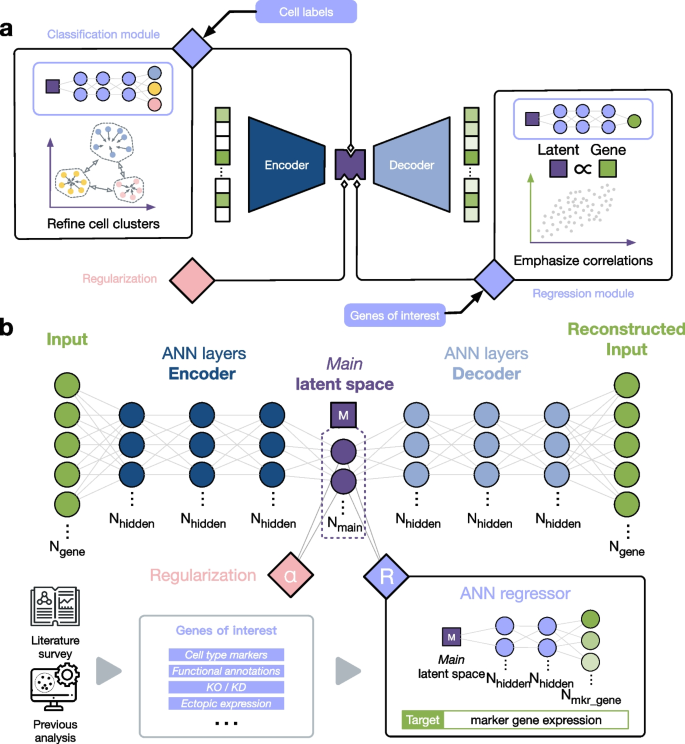
整体研究框架为:首先构建以自编码器为骨干、整合基因兴趣(GOI)模块和正则化组件的SAKURA降维框架,通过损失函数的动态优化实现全局数据结构保留与目标信号强化的平衡;随后在三个独立的单细胞数据集(人类胎儿胰腺细胞图谱、COVID-19患者CITE-seq数据、小鼠衰老脑单核RNA-seq数据)上验证框架的性能,重点测试其区分高度相似细胞亚群、识别稀有细胞类群的能力,并与当前主流的无监督和半监督降维方法进行多维度比较;最后通过调整知识输入内容、超参数等方式,验证框架的鲁棒性和适应性。
3.1 SAKURA框架构建与优化
实验目的:开发一种灵活、高效的知识引导式单细胞转录组降维框架,解决现有方法在稀有信号保留、外部知识获取成本等方面的局限。
方法细节:以编码器-解码器结构的自编码器为框架骨干,在瓶颈层添加基因兴趣(GOI)模块,通过整合L1、L2和余弦距离的回归损失函数,引导嵌入空间保留目标基因的表达信息;引入基于切片2-Wasserstein距离的正则化损失组件,防止嵌入空间出现表示坍塌,确保全局数据结构的有效利用;模型训练采用分阶段优化策略,先优化重建损失与正则化损失,再优化GOI损失,超参数(如正则化强度、GOI损失权重)根据数据集的聚类结果动态调整。
结果解读:SAKURA框架可灵活整合不同类型的知识输入(如基因列表、标注细胞),在保留全局数据结构的同时,显著强化目标基因相关的细胞信号;正则化组件有效避免了嵌入空间的过度浓缩,使不同细胞类群形成独立且分布合理的聚类;分阶段训练策略提升了模型的收敛速度和稳定性。
产品关联:文献未提及具体实验产品,领域常规使用Python的scikit-learn、Seurat、scvi-tools等生物信息学工具包进行单细胞数据处理与分析。
3.2 人类胎儿胰腺细胞图谱数据验证
实验目的:验证SAKURA在区分高度相似的胰岛内分泌细胞亚群中的性能,以及对未标注细胞的注释能力。
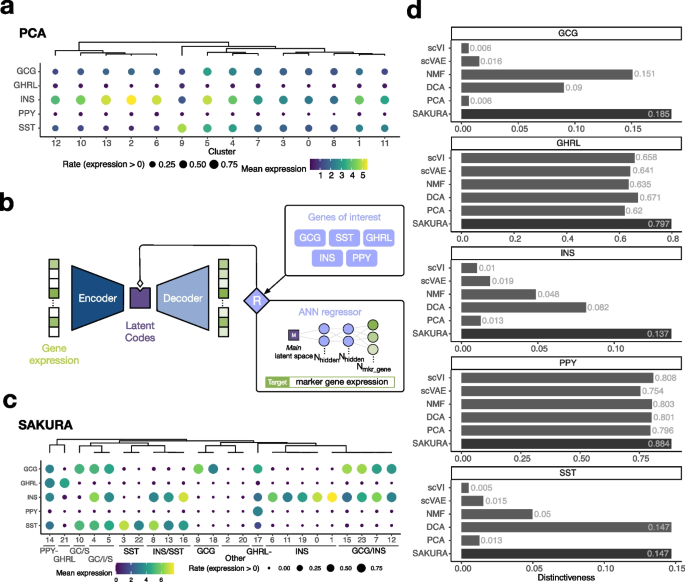
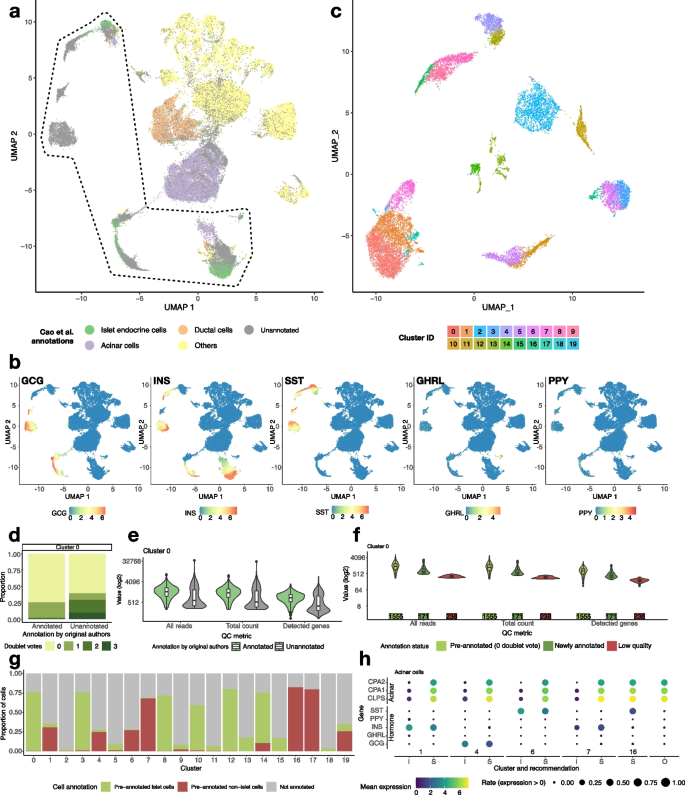
方法细节:获取人类胎儿胰腺单细胞RNA-seq数据,先通过标准无监督流程(PCA+Louvain聚类)分析,评估胰岛内分泌细胞亚群的区分效果;随后将5种胰岛激素基因(GCG、INS、SST、GHRL、PPY)作为知识输入SAKURA,生成细胞嵌入后重新进行聚类分析;通过独特性评分(量化目标基因在不同聚类中的表达差异)、内部验证指标(Davies-Bouldin Index、Average Silhouette Width、Calinski-Harabasz Index)评估SAKURA与其他无监督方法的性能差异;同时开发流程对未标注细胞进行注释,并识别可能存在错误标注的细胞。
结果解读:无监督流程无法有效区分5种胰岛内分泌细胞亚群,其聚类中激素基因的表达模式高度重叠;SAKURA生成的聚类中,5种激素基因的表达模式具有显著独特性(独特性评分显著高于其他无监督方法,P<0.01),成功区分出11种具有不同激素表达模式的胰岛细胞亚群,包括多激素表达的细胞类群;内部验证指标显示SAKURA的嵌入未发生明显数据扭曲,其聚类的紧凑性与分离度优于多数对比方法;此外,SAKURA成功为3520个原未标注或仅标注为“胰岛内分泌细胞”的样本分配了具体的亚型注释,并识别出1833个可能存在错误标注的细胞。
产品关联:文献未提及具体实验产品,领域常规使用Seurat进行单细胞数据预处理与聚类分析,DoubletDecon、DoubletFinder等工具进行 doublet 检测。
3.3 COVID-19患者CITE-seq数据验证
实验目的:验证SAKURA在区分CD4+和CD8+ T细胞亚群中的性能,并与半监督降维方法进行比较,同时测试框架对噪声知识输入的鲁棒性。
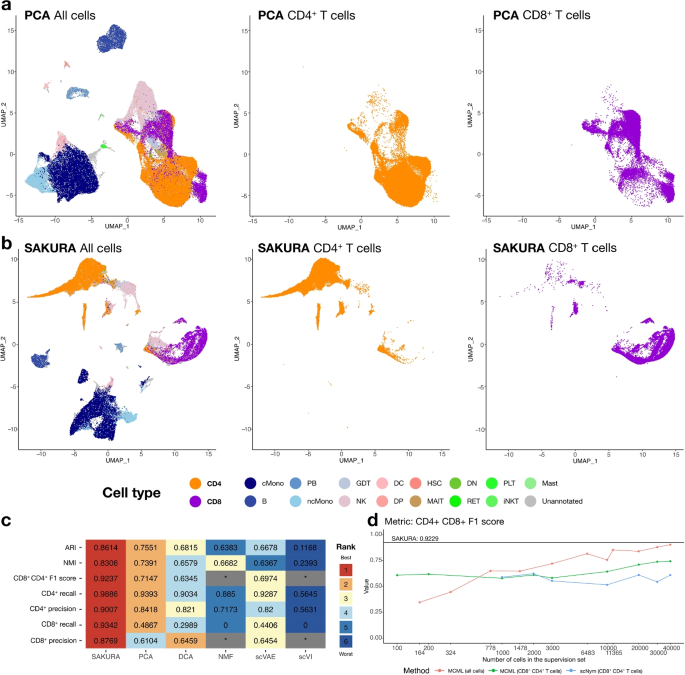
方法细节:获取COVID-19患者的CITE-seq数据,随机子采样200k细胞用于分析;先通过标准无监督流程分析CD4+和CD8+ T细胞的聚类效果;随后将CD8A/CD8B或CD4基因作为知识输入SAKURA,生成嵌入后进行聚类;通过外部验证指标(F1评分、Adjusted Rand Index、Normalized Mutual Information)评估SAKURA与5种无监督方法、2种半监督方法的性能差异;同时测试不同知识输入组合(缺失目标基因、添加无关基因)、超参数设置对SAKURA性能的影响。
结果解读:无监督流程无法有效分离CD4+和CD8+ T细胞,两类细胞在嵌入空间中高度混合;SAKURA生成的嵌入能清晰区分CD4+和CD8+ T细胞,其外部验证指标显著优于所有无监督对比方法,F1评分较PCA提升约25%;与半监督方法相比,SAKURA无需依赖标注细胞样本,性能更稳定,即使输入不完整或包含无关基因(如IFNG、LYZ、FN1)的知识列表,其性能仍优于或接近半监督方法;内部验证指标显示,SAKURA的嵌入未发生明显数据扭曲,其聚类质量在不同超参数设置下均保持稳定。
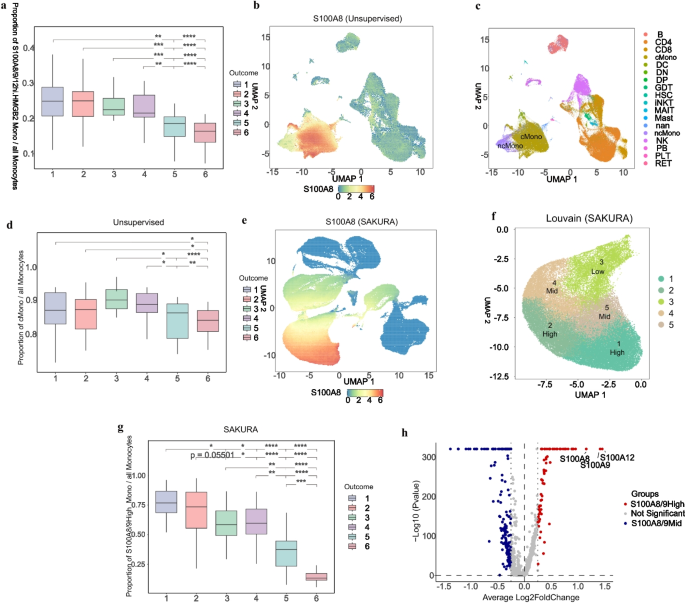
产品关联:文献未提及具体实验产品,领域常规使用CITE-seq技术平台进行转录组与蛋白组联合检测,Seurat进行多组学数据整合分析。
3.4 小鼠衰老脑单核RNA-seq数据验证
实验目的:验证SAKURA在识别稀有衰老细胞亚群中的性能,探索其在衰老相关研究中的应用价值。
方法细节:获取年轻与年老小鼠脑的单核RNA-seq数据,提取其中的小胶质细胞样本;先通过标准无监督流程分析衰老相关基因的表达分布;随后将CDKI基因(7个周期蛋白依赖性激酶抑制剂基因)和82个小鼠脑衰老特征基因作为知识输入SAKURA,生成嵌入后进行聚类;通过衰老相关基因集的表达比例、细胞来源(年轻/年老小鼠)评估聚类结果的生物学意义。
结果解读:无监督流程中,衰老相关基因(如CDKI、衰老特征基因)的表达在小胶质细胞中高度分散,无法形成独立的聚类;SAKURA成功识别出占小胶质细胞总数4.76%的稀有衰老细胞亚群(Cluster 10),该亚群中高表达CDKI和衰老特征基因的细胞比例显著高于其他亚群(P<0.001),且80%以上的细胞来自年老小鼠;进一步分析显示,该亚群同时高表达多种衰老相关基因集(如IFN-SASP基因、p53靶基因),验证了其作为衰老小胶质细胞的生物学特性。
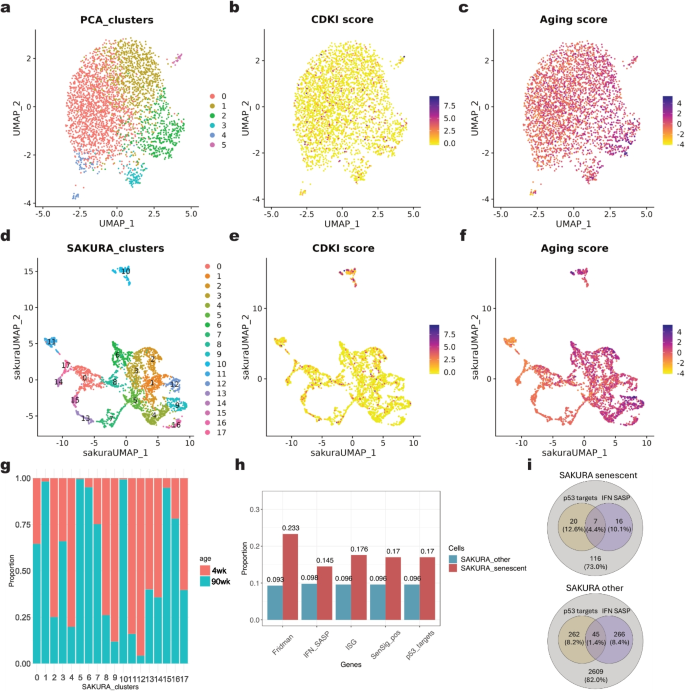
产品关联:文献未提及具体实验产品,领域常规使用单核RNA-seq技术平台进行细胞核转录组检测,cellxgene进行单细胞数据可视化。
4. Biomarker研究及发现成果解析
Biomarker定位与筛选逻辑
SAKURA涉及的Biomarker分为两类:引导降维的知识输入Biomarker和通过框架发现的细胞亚群特征Biomarker。知识输入Biomarker的筛选逻辑为:基于领域已知的细胞亚型标记基因(如胰岛激素基因、T细胞表面标记基因、衰老相关基因),直接作为知识输入引导降维;细胞亚群特征Biomarker的筛选逻辑为:通过SAKURA生成的嵌入聚类得到细胞亚群后,进行差异表达分析,筛选出在特定亚群中显著高表达的基因。
研究过程详述
- 胰岛内分泌细胞Biomarker:知识输入Biomarker为GCG、INS、SST、GHRL、PPY 5种激素基因,通过SAKURA降维聚类后,差异表达分析发现PLAGL1、CCSER1、ACVR1C等基因与INS表达呈特异性相关(仅在单独表达INS的细胞亚群中高表达),KCTD8、CNTN5、NLGN1等基因与SST表达呈特异性相关;独特性评分显示这些特征基因在对应亚群中的表达独特性显著高于无监督方法的聚类结果(P<0.01)。
- CD4+/CD8+ T细胞Biomarker:知识输入Biomarker为CD8A/CD8B或CD4基因,SAKURA降维后有效分离两类T细胞,即使输入无关基因(如IFNG、LYZ),其F1评分仍保持在0.9以上,显著高于无监督方法的0.7左右;差异表达分析进一步验证了CD4、CD8A/B在对应T细胞亚群中的特异性表达。
- 衰老小胶质细胞Biomarker:知识输入Biomarker为7个CDKI基因和82个衰老特征基因,SAKURA识别出的Cluster 10中,高表达IFN-SASP基因的细胞占比为60%(其他亚群为20%,n=该亚群细胞数,P<0.001),高表达p53靶基因的细胞占比为55%(其他亚群为18%,n=该亚群细胞数,P<0.001);该亚群还特异性高表达Cdkn2a、Cdkn1a等衰老核心标记基因。
核心成果提炼
SAKURA框架的核心成果包括:1)首次证明以基因列表作为知识输入的引导式降维方法,可在不依赖标注细胞的前提下,有效保留稀有细胞亚群、高度相似细胞亚群的关键生物信号,填补了现有方法的技术空白;2)在人类胎儿胰腺数据中发现了11种具有不同激素表达模式的胰岛细胞亚群,其中多激素表达细胞亚群的发现为胰岛发育机制研究提供了新视角;3)在COVID-19数据中发现S100A8/9高表达的单核细胞亚群,其比例与疾病严重程度显著相关(P<0.001),为COVID-19的临床预后评估提供了潜在Biomarker;4)在小鼠衰老脑数据中识别出稀有衰老小胶质细胞亚群,为衰老相关神经疾病的发病机制研究提供了新的细胞模型。这些成果均通过严格的统计学验证,且未对全局数据结构造成明显扭曲,具有较高的生物学可信度和临床应用潜力。