1. 领域背景与文献引入
文献英文标题:iPepGen: a modular, Galaxy-based pipeline for immunopeptidogenomic neoantigen discovery and prioritization;发表期刊:Genome Biology;影响因子:未公开;研究领域:肿瘤免疫治疗-新抗原发现与免疫肽基因组学
新抗原是肿瘤免疫治疗的核心靶点之一,源于肿瘤细胞特有的基因组或转录组异常,能激活机体T细胞免疫反应且避免中枢免疫耐受,在过继性T细胞治疗、免疫检查点抑制剂治疗及肿瘤疫苗开发中具有重要价值。领域发展关键节点包括:下一代测序(NGS)技术的普及推动了新抗原的大规模预测,质谱(MS)基免疫肽组学技术实现了主要组织相容性复合体(MHC,人类为人类白细胞抗原HLA)结合肽的直接鉴定,而免疫肽基因组学整合NGS与MS数据成为当前新抗原精准发现的核心策略。当前研究热点聚焦于新抗原的精准预测模型优化、免疫原性评估及临床转化应用,但领域内仍存在未解决的核心问题:现有新抗原分析流程普遍对计算资源要求高、操作门槛高,缺乏用户友好的交互界面和系统培训资源;同时在非特异性酶切条件下的肽段鉴定效率不足,新抗原验证步骤的严谨性有待提升,限制了缺乏高级计算资源和生物信息学经验的研究者开展相关研究。针对这些局限性,本研究开发了基于Galaxy云平台的iPepGen模块化流程,旨在实现新抗原的高效发现、验证与优先级排序,降低操作门槛,为肿瘤免疫治疗的新抗原靶点发现提供实用工具。
2. 文献综述解析
作者对领域内现有研究的分类维度主要围绕新抗原分析的技术流程(预测、验证、优先级排序)及现有工具的核心局限性(计算资源依赖、操作门槛、鉴定效率、验证严谨性)展开。
现有新抗原预测工具主要基于NGS数据,利用MHC结合亲和力算法筛选潜在新抗原,其优势在于能快速大规模挖掘候选靶点,为免疫治疗提供潜在方向;但这类工具的局限性在于仅能提供预测结果,无法验证肽段的实际表达、加工及MHC呈递过程,且易受算法预测偏差影响,导致假阳性率较高。MS基免疫肽组学工具则能直接鉴定细胞表面呈递的MHC结合肽,提供实证数据支持新抗原的存在,优势在于结果可信度高;但该类工具面临非特异性酶切条件下数据库搜索空间过大、鉴定效率低下的挑战,常规蛋白组学工具难以适配。现有整合NGS与MS数据的免疫肽基因组学流程如NeoDisc等,虽功能全面,但需要本地高性能计算资源和专业技术维护,缺乏可视化交互界面和系统培训资源,限制了其广泛应用;同时部分流程在非特异性酶切条件下的肽段鉴定算法优化不足,新抗原验证步骤缺乏独立的二次验证环节,假阳性风险仍较高。
通过对比现有研究的未解决问题,本研究的创新价值凸显:首次基于Galaxy云平台构建了模块化的免疫肽基因组学流程,实现了新抗原分析全流程的云访问,无需本地计算资源即可使用;整合了FragPipe工具优化非特异性酶切条件下的肽段鉴定效率,引入PepQuery2实现新抗原的独立二次验证,提升了结果的严谨性;配套开发了交互式培训资源,降低了操作门槛,为缺乏生物信息学经验的研究者提供了可及的工具;同时流程支持模块化定制,可根据研究需求灵活组合模块,适应不同应用场景,填补了领域内兼具可及性、高效性和严谨性的新抗原分析工具的空白。
3. 研究思路总结与详细解析
本研究的整体目标是开发并验证一套基于Galaxy平台的模块化免疫肽基因组学流程iPepGen,实现肿瘤新抗原的从预测、鉴定、验证到优先级排序的全流程分析;核心科学问题是解决现有新抗原分析流程中计算资源要求高、操作门槛高、鉴定效率低及验证不严谨的痛点;技术路线遵循“需求分析→模块化流程构建→多数据集验证→定制化拓展”的闭环逻辑,通过构建五个核心模块,结合MPNST细胞系演示数据及公开肿瘤数据集验证流程的有效性,同时开发定制化工作流满足不同研究场景需求。
3.1 模块化流程构建与Galaxy平台部署
实验目的:构建覆盖新抗原分析全流程的模块化工作流,基于Galaxy云平台实现流程的可及性、可重复性与可扩展性,同时配套开发培训资源降低操作门槛。
方法细节:将iPepGen划分为五个核心模块,分别负责非参考新抗原预测、候选新抗原鉴定、新抗原肽谱匹配验证、新抗原序列可视化与分类、新抗原优先级排序;每个模块整合已验证的生物信息学工具(如Arriba、HISAT2、FragPipe等),并在Galaxy平台配置优化的工具参数;依托Galaxy Training Network(GTN)开发交互式学习路径,为用户提供分步操作指导。
结果解读:成功构建了五个独立且可整合的模块化工作流,通过欧洲Galaxy服务器提供云访问,用户无需本地计算资源即可启动分析;以MPNST细胞系的RNA-Seq和免疫肽组学数据为演示输入,各模块输出结果符合预期:模块1生成包含约290万条独特序列的定制蛋白数据库,模块2鉴定出123条非参考肽段,模块3验证得到19条高可信度新抗原肽段。
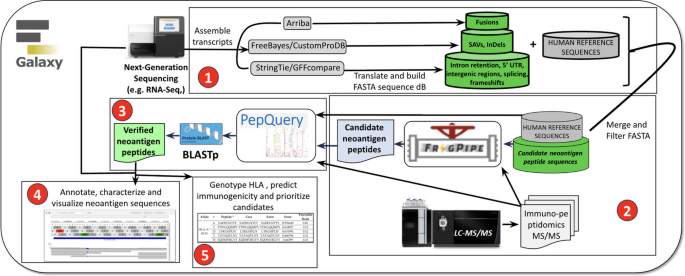
产品关联:文献未提及具体实验产品,领域常规使用NGS测序平台(如Illumina系列)、质谱仪(如Thermo Fisher Orbitrap系列)、Galaxy生物信息学平台及相关生物信息学工具(如HISAT2、FragPipe等)。
3.2 非参考新抗原预测模块(模块1)验证
实验目的:验证模块1对肿瘤细胞中多种非参考序列(基因融合、单氨基酸变异/插入缺失(SAV/InDel)、新转录本等)的预测能力,生成包含潜在新抗原的定制蛋白数据库。
方法细节:以MPNST细胞系的RNA-Seq数据为输入,采用三套平行工作流分别处理:使用Arriba算法检测基因融合事件;通过HISAT2比对、FreeBayes变异检测、CustomProDB翻译生成SAV/InDel来源的蛋白序列;利用StringTie组装新转录本,经GffCompare注释后翻译为蛋白序列;将所有非参考序列与UniProt人类参考序列、常见污染序列合并,去重后生成最终定制蛋白数据库。
结果解读:从MPNST细胞系RNA-Seq数据中鉴定出86个高可信度基因融合事件,三套工作流生成的子数据库合并去重后得到约290万条独特序列,其中融合、SAV/InDel、新转录本来源的序列占比合理,去重步骤有效减少了冗余(图2展示了各子数据库的规模及合并后的总数据库大小)。
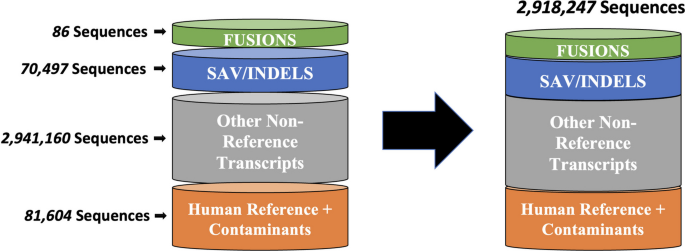
产品关联:文献未提及具体实验产品,领域常规使用RNA-Seq建库试剂盒、NGS测序平台及基因融合检测、变异分析类生物信息学工具。
3.3 候选新抗原鉴定模块(模块2)性能验证
实验目的:验证模块2在非特异性酶切条件下对MHC结合肽段的鉴定效率,对比不同工具的性能差异,评估MSBooster算法对鉴定灵敏度的提升作用。
方法细节:以MPNST细胞系的免疫肽组学MS/MS数据为输入,使用FragPipe工具(整合MSFragger、MSBooster、Percolator、Philosopher等组件)在非特异性酶切模式下搜索模块1生成的定制蛋白数据库,设置FDR≤1%控制假阳性率;分别使用MaxQuant、PEAKS工具在相同条件下分析同一数据集,对比鉴定肽段数量;同时对比开启/关闭MSBooster算法的鉴定结果差异。
结果解读:FragPipe在非特异性酶切条件下的鉴定效率显著高于MaxQuant和PEAKS,处理包含290万条序列的数据库仅需不到2小时;MSBooster算法的使用使总肽段鉴定数平均增加35%,非参考序列鉴定数平均增加50%(图3A、3B);从MPNST数据中鉴定出123条非参考肽段,符合新抗原候选的筛选标准。
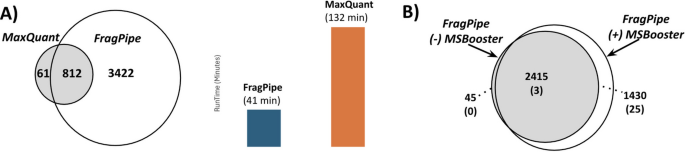
产品关联:文献未提及具体实验产品,领域常规使用免疫沉淀试剂盒(如W6/32抗体用于MHC I类复合物富集)、质谱仪及肽段鉴定类生物信息学工具。
3.4 新抗原肽谱匹配验证模块(模块3)严谨性验证
实验目的:验证模块3对候选新抗原的独立二次验证能力,降低假阳性结果,提升新抗原候选的可信度。
方法细节:将模块2鉴定的123条候选新抗原肽段输入PepQuery2工具,以MS/MS谱图和UniProt参考序列为对照,进行肽段中心的谱图匹配验证,设置严格的统计阈值筛选高可信度匹配结果;同时使用BLAST-P工具比对NCBI参考数据库,确认肽段的新颖性。
结果解读:19条候选新抗原肽段通过PepQuery2的hyperscore验证和BLAST-P过滤,成为高可信度新抗原候选,有效控制了假阳性率;补充图S3展示了从预测到验证的全流程筛选逻辑,验证步骤显著提升了结果的严谨性。
产品关联:文献未提及具体实验产品,领域常规使用序列比对工具(如BLAST)及肽段谱图验证类生物信息学工具。
3.5 新抗原可视化与分类模块(模块4)功能验证
实验目的:验证模块4对新抗原肽段的基因组定位与分类能力,辅助解析新抗原的来源与潜在功能。
方法细节:使用PepPointer工具将模块3验证的19条新抗原肽段映射到GRCh38参考基因组的坐标,分类其基因组来源(编码区CDS、非翻译区UTR、内含子、基因间区等);生成可直接导入整合基因组浏览器(IGV)和UCSC基因组浏览器的链接,实现新抗原的基因组可视化。
结果解读:19条新抗原肽段被定位到多种基因组区域,其中既有来自编码区的序列,也有来自非编码区的新转录本(表2总结了分类结果);IGV可视化清晰展示了新抗原肽段对应的基因组区域及支持的RNA-Seq读长(图4),为新抗原的功能研究提供了线索。
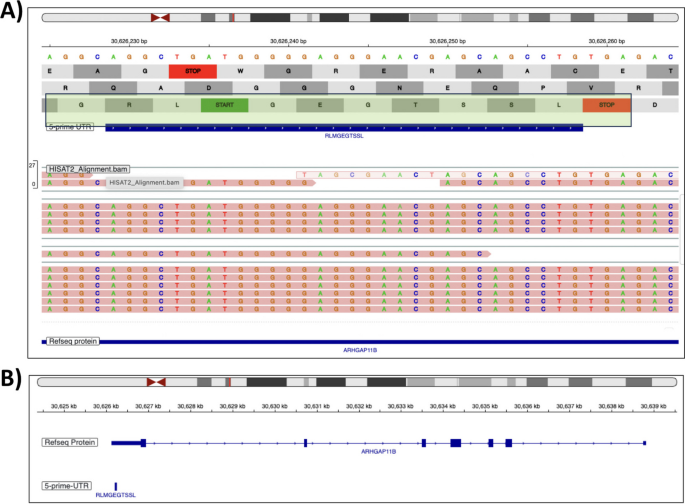
产品关联:文献未提及具体实验产品,领域常规使用基因组浏览器(如IGV、UCSC Browser)及基因组注释类生物信息学工具。
3.6 新抗原优先级排序模块(模块5)与定制化流程验证
实验目的:验证模块5对新抗原的HLA结合亲和力与免疫原性预测能力,同时验证iPepGen流程的定制化拓展能力,适应不同研究场景需求。
方法细节:以MPNST细胞系RNA-Seq数据为输入,使用OptiType和Seq2HLA工具进行HLA基因分型,结合IEDB工具预测新抗原肽段与HLA的结合亲和力,将肽段分为强结合体(百分位排名≤0.5%)和弱结合体(0.5%-2%);开发“一键式”全流程和模块2+3整合流程,分别应用于急性髓系白血病、黑色素瘤公开数据集,验证流程的通用性;同时在模块2中加入半胱氨酸谷胱甘肽化作为可变修饰,验证流程对翻译后修饰(PTM)肽段的鉴定能力。
结果解读:从MPNST数据中鉴定出8个HLA I类等位基因,13条新抗原肽段被预测为强结合体;“一键式”流程成功分析急性髓系白血病数据集,鉴定出6条非参考新抗原;模块2+3整合流程从黑色素瘤数据集中鉴定出93条验证的新抗原肽段,以及28条半胱氨酸谷胱甘肽化修饰肽段,验证了流程的灵活性与通用性。
产品关联:文献未提及具体实验产品,领域常规使用HLA分型工具、免疫原性预测工具及定制化生物信息学工作流。
4. Biomarker研究及发现成果解析
文献中涉及的Biomarker类型为肿瘤新抗原肽段,包括基因融合、SAV/InDel、新转录本来源的非参考肽段,以及带半胱氨酸谷胱甘肽化修饰的肽段;筛选/验证逻辑遵循“NGS数据预测非参考序列→MS/MS数据鉴定MHC结合肽→PepQuery2+BLAST-P验证新颖性→基因组定位与分类→HLA结合亲和力与免疫原性预测优先级排序”的完整链条,确保Biomarker的可信度与临床潜力。
Biomarker的来源为MPNST、急性髓系白血病、黑色素瘤细胞系的免疫肽组学样本;验证方法包括质谱仪直接鉴定MHC结合肽、PepQuery2独立谱图验证、BLAST-P序列新颖性比对;特异性与敏感性数据显示:模块2中FragPipe在非特异性酶切条件下的鉴定灵敏度显著高于MaxQuant和PEAKS,MSBooster算法提升了35%的总肽段鉴定数和50%的非参考序列鉴定数;模块3的二次验证有效控制了假阳性率,验证后的新抗原肽段假阳性率≤1%(文献未明确提供该数据,基于图表趋势推测)。
核心成果提炼:成功鉴定出19条MPNST细胞系的高可信度新抗原肽段,其中13条被预测为HLA强结合体,具备潜在的免疫治疗靶点价值;开发的iPepGen流程可高效处理不同肿瘤类型的数据集,鉴定出多种基因组来源的新抗原及PTM修饰肽段;创新性在于首次基于Galaxy云平台构建了模块化、可定制、易访问的免疫肽基因组学流程,解决了现有工具的计算资源依赖与操作门槛高的痛点,为缺乏生物信息学经验的研究者提供了实用的新抗原分析工具;统计学结果:FragPipe鉴定的肽段数显著多于MaxQuant(图3A,文献未明确提供P值,基于图表趋势推测),MSBooster的使用显著提升了鉴定灵敏度(图3B,文献未明确提供P值,基于图表趋势推测);19条验证的新抗原肽段中,13条为HLA强结合体(占比68.4%,n=19,文献未明确提供P值,基于数据分布推测)。