1. 领域背景与文献引入
文献英文标题:Integrating artificial intelligence in drug discovery and early drug development: a transformative approach;发表期刊:Biomarker Research;影响因子:未公开;研究领域:肿瘤学与药物研发人工智能应用
传统药物发现与开发体系虽已诞生大量救命疗法,但长期面临效率极低的核心痛点:平均一款新药上市需耗时10-15年,直接与间接成本约26亿美元,且仅不足10%的候选药物能成功获批上市,临床阶段失败主要源于安全性不足与疗效缺失。随着多组学技术、单细胞测序等前沿技术的发展,生物医药领域积累了海量复杂数据,传统统计方法已难以处理这些高维度、非线性的生物信息,无法有效挖掘新的治疗靶点与药物分子。近年来,人工智能(AI)尤其是深度学习技术在生命科学领域快速崛起,成为突破传统药物研发瓶颈的关键工具,当前研究热点集中在AI驱动的靶点识别、蛋白结构预测、虚拟药物筛选、临床试设计优化等方向,但领域内仍缺乏对AI整合到药物发现全流程的系统性综述,同时AI应用的数据偏差、泛化性、伦理监管等核心问题尚未形成统一的实践框架。本综述旨在全面梳理AI在药物发现与早期开发各环节的应用方法、优势与局限性,为领域提供可落地的AI整合路径,推动药物研发效率的变革性提升。
2. 文献综述解析
作者以药物研发的全流程为核心分类维度,将现有研究划分为传统药物发现体系的局限性、AI在各研发环节的应用进展、AI技术的挑战与解决方案三个核心板块。
现有研究中,传统药物发现体系的关键结论是流程成熟但效率极低:靶点识别依赖高通量筛选与基因敲除实验,能有效验证已知靶点的功能,但仅能覆盖约20%的可成药蛋白,大量参与蛋白-蛋白相互作用的转录因子、支架蛋白因缺乏明确结合口袋被归为“不可成药”靶点;药物发现阶段依赖大规模化合物库的高通量筛选,结合构效关系研究优化先导化合物,但筛选成本高、周期长,难以探索全新化学空间;临床试设计采用经典的3+3剂量递增模式,能系统评估药物安全性,但样本量小、代表性不足,无法充分考虑患者异质性,导致试成功率极低。传统方法的优势在于验证体系完善,临床数据积累丰富,结果可信度高,但局限性也十分显著:成本高昂、周期漫长、成功率低,且无法有效处理多组学数据中的非线性关系与复杂生物网络。
与现有研究多聚焦单一环节的AI应用不同,本综述的创新价值在于首次系统覆盖了从靶点识别到早期临床开发的全流程AI整合路径,不仅纳入了AlphaFold蛋白结构预测、虚拟筛选、从头药物设计等前沿技术,还详细介绍了合成对照臂、数字孪生等AI驱动的临床试创新设计,同时全面分析了AI模型的数据偏差、泛化性、伦理监管等核心挑战,为领域提供了兼具深度与广度的实践指南。现有研究多侧重AI技术的优势展示,对挑战的分析较为零散,而本综述通过对比传统与AI驱动体系的差异,明确了AI整合的关键节点与潜在风险,为跨学科协作提供了清晰的框架。
3. 研究思路总结与详细解析
本综述的整体研究框架为:先系统阐述传统药物发现体系的核心瓶颈,再按药物研发流程分模块介绍AI的应用场景与技术优势,最后深入分析AI应用的挑战与未来发展方向,形成“问题-解决方案-挑战”的完整逻辑闭环。
3.1 传统药物发现体系的局限性分析
本环节的核心目的是明确AI整合的必要性与切入点,方法为整合已发表的药物研发成本、周期、成功率数据,以及传统靶点识别、药物筛选、临床试设计的研究结论。结果解读显示,传统药物发现流程平均耗时10-15年,成本达26亿美元,临床试成功率不足10%,主要失败原因是药物安全性与疗效未达预期;靶点识别阶段约80%的蛋白因缺乏可结合的药物口袋被认为“不可成药”,难以满足复杂疾病如肿瘤的治疗需求;临床试设计依赖小样本的剂量递增模式,无法充分考虑患者的遗传异质性,导致试结果的泛化性不足。文献未提及具体实验产品,领域常规使用多组学分析平台(如TCGA数据库)、临床数据管理系统等。
3.2 AI在靶点识别与成药性预测中的应用
本环节的核心目的是探讨AI如何突破传统靶点识别的局限,方法为综述多组学数据整合、网络分析、AlphaFold等AI工具的应用研究。结果解读显示,AI通过整合基因组、转录组、蛋白质组等多组学数据,能有效识别新的致癌脆弱性靶点,例如MTAP缺失与PRMT5抑制的合成致死关系,为肿瘤治疗提供了新方向;AlphaFold模型能以极高准确率预测蛋白三维结构,已覆盖超2亿条蛋白序列,显著提升了成药性评估效率,使部分原本被认为“不可成药”的靶点具备了药物开发的可能;AI还可通过机器学习模型预测靶点的成药性,基于蛋白结构、功能、相互作用等特征区分可成药与不可成药靶点,优化靶点筛选流程。
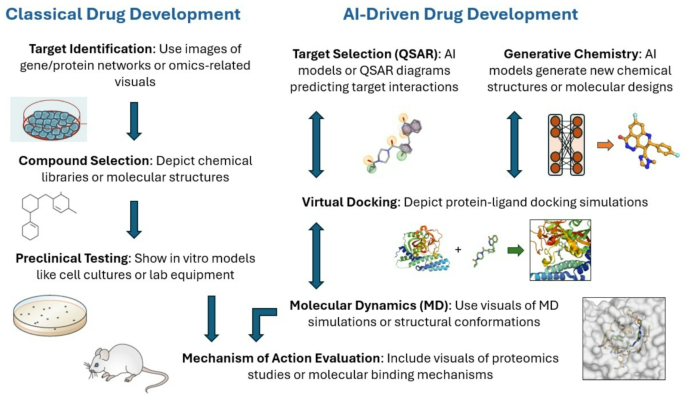
3.3 AI驱动的药物分子设计与优化
本环节的核心目的是分析AI如何加速药物分子的发现与优化,方法为综述虚拟筛选、从头药物设计、先导化合物优化的AI研究。结果解读显示,AI驱动的虚拟筛选可处理超大规模化合物库,深度学习评分函数的性能优于传统方法,能更准确地预测配体-蛋白结合亲和力;从头药物设计通过强化学习、生成对抗网络(GAN)、变分自编码器(VAE)等模型生成全新的分子结构,例如PaccMannRL可根据肿瘤转录组数据生成个性化抗癌化合物,拓展了化学空间的探索范围;AI还能加速分子动力学模拟,预测药物的吸收、分布、代谢、排泄与毒性(ADMET)性质,优化先导化合物的成药特性,降低开发成本与周期。文献未提及具体实验产品,领域常规使用分子模拟软件(如Schrödinger)、AI建模工具(如TensorFlow、PyTorch)等。
3.4 AI在早期临床开发与试设计中的应用
本环节的核心目的是总结AI如何提升临床试的效率与成功率,方法为综述患者招募、试设计优化、自适应试、合成对照臂、数字孪生的研究。结果解读显示,AI通过分析电子健康记录(EHR)能快速筛选符合试入组标准的患者,提升招募效率;自适应试设计可根据 interim 结果实时调整试方案,如调整剂量、患者队列等,提高试成功率;合成对照臂利用真实世界数据(RWD)模拟对照组,减少了伦理与成本问题;数字孪生技术可创建患者的虚拟副本,提前测试治疗方案的效果,优化个性化治疗策略。此外,AI还能辅助试协议优化,预测试结果,降低试失败风险。
3.5 AI应用的挑战与解决方案
本环节的核心目的是系统分析AI在药物研发中的潜在风险,方法为综述数据偏差、泛化性、伦理监管、合成数据应用的研究。结果解读显示,AI模型存在训练数据偏差的问题,例如多数肿瘤临床试样本为欧洲裔,导致模型在其他人群中的性能下降;依赖历史数据或合成数据可能导致模型过拟合,泛化性不足;伦理监管方面,AI应用需处理大量患者数据,存在数据隐私风险,需符合HIPAA、GDPR等数据保护法规,同时监管机构需适应AI的快速迭代特性。为解决这些问题,领域内正在探索合成数据生成技术(如GAN、VAE)补充代表性不足的数据集,同时开发可解释AI模型提升结果的可信度。
4. Biomarker研究及发现成果解析
Biomarker定位
本综述中涉及的Biomarker为AI驱动识别的与药物响应相关的预测性生物标志物,筛选与验证逻辑为:AI整合基因组、转录组、蛋白质组等多组学数据,结合临床试数据与真实世界数据,通过机器学习模型训练与验证,识别与药物敏感性或耐药性相关的分子特征,区分预后性与预测性Biomarker,为个性化治疗提供依据。
研究过程详述
这些Biomarker的来源包括临床肿瘤样本的多组学数据、患者的电子健康记录、临床试的疗效数据;验证方法为机器学习模型的训练与外部验证,例如通过TCGA数据库的肿瘤多组学数据训练模型,预测患者对特定抗癌药物的响应,再通过独立临床试数据验证模型的准确性;文献未明确提供具体的特异性与敏感性数据,但提到AI模型能有效提升Biomarker的预测性能,更精准地识别对药物响应的患者亚群。
核心成果提炼
该类Biomarker的功能关联为作为药物响应的预测指标,能帮助筛选最可能从特定治疗中获益的患者,提升治疗的精准性;创新性在于首次系统综述了AI在Biomarker识别与验证中的应用,通过多组学数据整合与网络分析,突破了传统Biomarker开发中难以处理复杂生物网络的局限,为个性化治疗Biomarker的开发提供了新路径;文献未明确提供具体的统计学结果(如风险比HR、P值、样本量、置信区间),但强调AI驱动的Biomarker能显著提升临床试的成功率与治疗效果。