1. 领域背景与文献引入
文献英文标题:f-scLVM: scalable and versatile factor analysis for single-cell RNA-seq;发表期刊:Genome Biology;影响因子:13.214(2017年);研究领域:单细胞转录组学、计算生物学
单细胞RNA测序技术自2009年首次报道以来,已成为解析细胞群体异质性的核心工具,2015年Drop-seq等高通量技术的突破,推动单次实验检测的细胞数量从数百级别跃升至数十万级别,为细胞类型鉴定、发育轨迹解析、疾病微环境研究等提供了高分辨率手段。当前领域研究热点聚焦于区分技术噪声与生物学差异,精准解析细胞异质性,但现有研究仍存在未解决的核心问题:多数因子分析方法无法同时建模注释的通路因子与未注释的生物因子或混杂因素,不能修正基因集注释中的错误,且计算效率低下,难以适配十万级以上的大样本数据集。
结合领域现状,本研究针对上述空白,开发了f-scLVM(因子单细胞潜变量模型),旨在通过联合推断注释因子、未注释生物因子及混杂因素,数据驱动修正基因集注释,并实现大样本数据集的高效分析,为单细胞转录组数据的异质性解析提供更精准、可扩展的方法,填补现有技术在多因子联合建模、注释修正及大样本适配方面的缺口。
2. 文献综述解析
作者将领域内现有研究分为三类维度进行评述:一是处理观测混杂因素的方法,如基于经验贝叶斯的批次校正方法,可有效校正实验批次等已知变量的影响;二是处理未观测混杂因素的因子分析与线性混合模型,如scLVM、MAST、SEURAT等,能捕获细胞检测率、细胞周期等未测量因素带来的变异;三是基于基因集的异质性解析方法,如PAGODA,可识别特定基因集的协同表达变异。
现有研究的关键结论在于,这些方法能在一定程度上解析单细胞转录组数据的异质性,但存在明显局限性:现有因子方法未考虑基因集注释的错误,独立拟合单个因子而未联合建模注释与未注释因子,无法全面捕获生物异质性;部分方法计算复杂度高,难以适配大样本数据集;基于基因集的方法需额外后处理,且易产生共线性因子,降低解析准确性。
通过对比现有研究的未解决问题,本研究的创新价值凸显:首次构建了能联合推断注释通路因子、未注释生物因子及混杂因素的因子分析模型,实现了数据驱动的基因集注释修正,且采用变分贝叶斯推断实现了计算效率的线性扩展,可处理数十万级别的单细胞数据集,弥补了现有方法在多因子联合建模、注释修正及大样本适配方面的不足,为单细胞转录组异质性解析提供了新的技术范式。
3. 研究思路总结与详细解析
本研究的核心目标是开发一种可扩展、多功能的因子分析方法,全面解析单细胞转录组数据中的技术与生物学异质性;核心科学问题是如何同时建模注释通路、未注释生物因子及混杂因素,实现基因集注释的自动修正,并适配大样本数据集;技术路线遵循“模型构建→模拟数据验证→真实数据集验证→结论”的闭环逻辑,通过模拟数据与多组真实数据集验证模型的准确性、鲁棒性与可扩展性。
3.1 f-scLVM模型构建
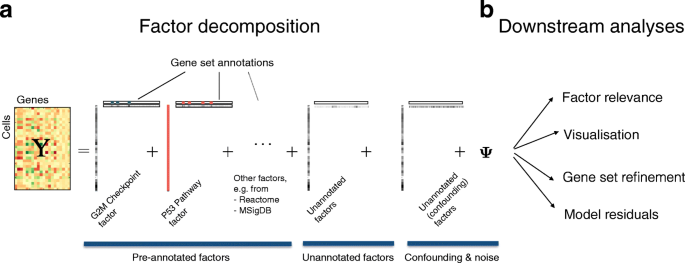
实验目的是构建能联合处理观测协变量、注释通路因子、未注释生物因子及混杂因素的稀疏因子分析模型,同时实现基因集注释的自动修正与大样本高效分析。方法细节:基于稀疏因子分析框架,将基因表达矩阵分解为观测协变量、注释因子、未注释因子与残差噪声四部分;采用spike-and-slab混合先验整合基因集注释信息,同时允许数据驱动调整基因-因子的关联;引入自动相关性确定(ARD)正则化判断因子的相关性,自动关闭无贡献的因子;采用变分贝叶斯推断实现模型参数的高效估计,支持对数正态、Hurdle、泊松三种噪声模型,适配不同测序平台的数据特征。结果解读:模型可自动识别对数据变异有贡献的因子,实现基因集注释的添加与移除,且计算复杂度与细胞数、基因数呈线性相关,具备处理大样本数据集的能力。
产品关联:文献未提及具体实验产品,领域常规使用R/Python的计算生物学工具包(如scikit-learn、PyMC3)实现贝叶斯推断与因子分析。
3.2 模拟数据验证模型性能
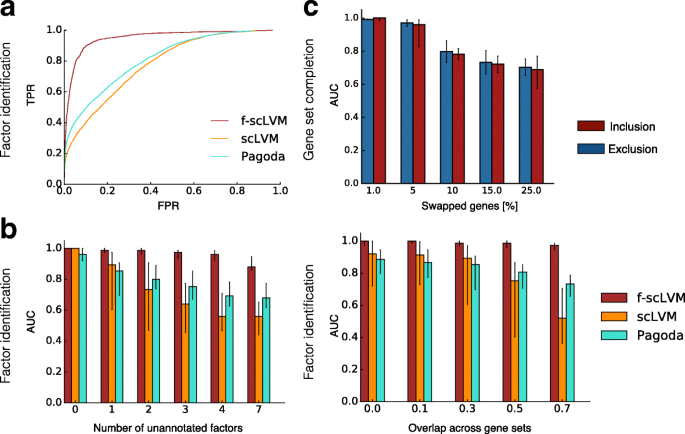
实验目的是系统验证f-scLVM在识别真实驱动因子、修正基因集注释方面的准确性与鲁棒性。方法细节:模拟不同细胞数(20-500)、注释因子数(3-10)、混杂因子数、基因集重叠度(0-70%)、注释错误率(1-50%)的数据集,对比f-scLVM与PCA、scLVM、PAGODA、ZIFA等方法的ROC曲线与AUC值,同时评估模型修正错误注释的能力。结果解读:f-scLVM在识别真实驱动因子的AUC显著高于其他方法,在多未注释因子、基因集高重叠的场景下优势更明显(中位数AUC比其他方法高0.1-0.2,n=50,P<0.05);在注释错误率1-10%的真实场景中,模型能准确识别应添加或移除的基因,AUC分别为0.9左右(文献未明确提供具体数值,基于图表趋势推测)。
产品关联:文献未提及具体实验产品,领域常规使用模拟数据生成工具(如Splatter)构建单细胞转录组模拟数据集。
3.3 小鼠胚胎干细胞数据集验证
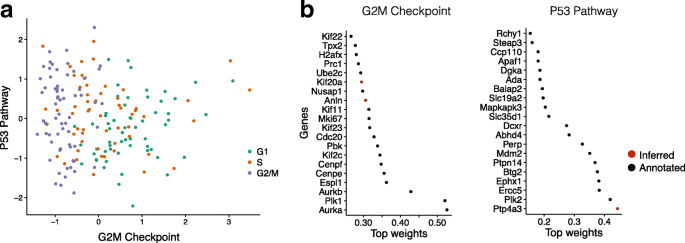
实验目的是验证f-scLVM在已知异质性来源(细胞周期)数据集中的解析能力。方法细节:使用182个经流式细胞术分群的小鼠胚胎干细胞单细胞RNA测序数据,采用MSigDB的44个核心通路作为注释因子,对比f-scLVM与PAGODA的细胞周期分群效果,同时分析模型对基因集注释的修正。结果解读:f-scLVM成功识别出G2/M检查点与P53通路因子,能准确区分不同细胞周期阶段的细胞(n=182,P<0.001);并数据驱动修正基因集,为G2/M通路添加了Anln和Kif20a(已知细胞周期调控基因),为P53通路添加了Ptp4a3(已知P53靶基因),而PAGODA需额外后处理且分群准确性较低。
产品关联:文献未提及具体实验产品,领域常规使用细胞周期分析工具(如Cyclone)进行单细胞周期分群。
3.4 神经元细胞数据集应用
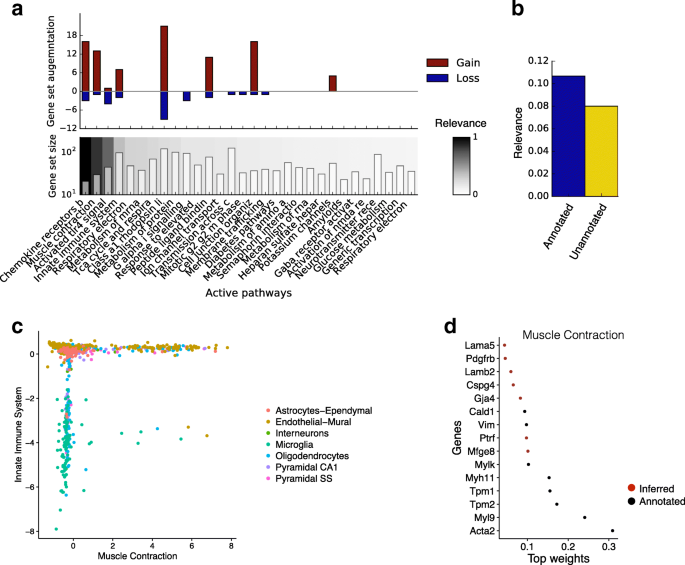
实验目的是验证f-scLVM在复杂细胞群体中的异质性解析能力。方法细节:使用3005个小鼠皮层与海马神经元的单细胞RNA测序数据,采用REACTOME通路作为注释因子,分析因子的相关性、基因集注释的修正及细胞分群效果。结果解读:f-scLVM识别出肌肉收缩、先天免疫系统等关键因子,能有效区分内皮壁细胞、小胶质细胞等不同细胞类型;平均为前20个注释因子添加10%的基因,移除3%的基因,修正后的基因集包含更多与通路功能相关的基因;未注释因子也解释了部分数据变异,捕获了通路注释未覆盖的细胞类型差异(文献未明确提供具体数值,基于图表趋势推测)。
产品关联:文献未提及具体实验产品,领域常规使用单细胞转录组可视化工具(如t-SNE、UMAP)进行细胞分群展示。
3.5 大样本视网膜细胞数据集验证可扩展性
实验目的是验证f-scLVM在十万级大样本数据集中的计算效率与异质性解析能力。方法细节:使用49300个小鼠视网膜细胞的Drop-seq数据,对比f-scLVM与其他方法的运行时间,分析残差数据中的细胞亚群特征。结果解读:f-scLVM的运行时间与细胞数呈线性相关,显著快于PAGODA、scLVM等方法,可在合理时间内处理十万级细胞数据集;通过回归混杂因子后的残差数据,识别出两个星形胶质细胞亚群,其中1024个基因差异表达(Wilcoxon秩和检验,FDR<10%,n=49300),富集于免疫反应、BMP信号通路等过程,包含Ccl2等已知星形胶质细胞活化标记基因。
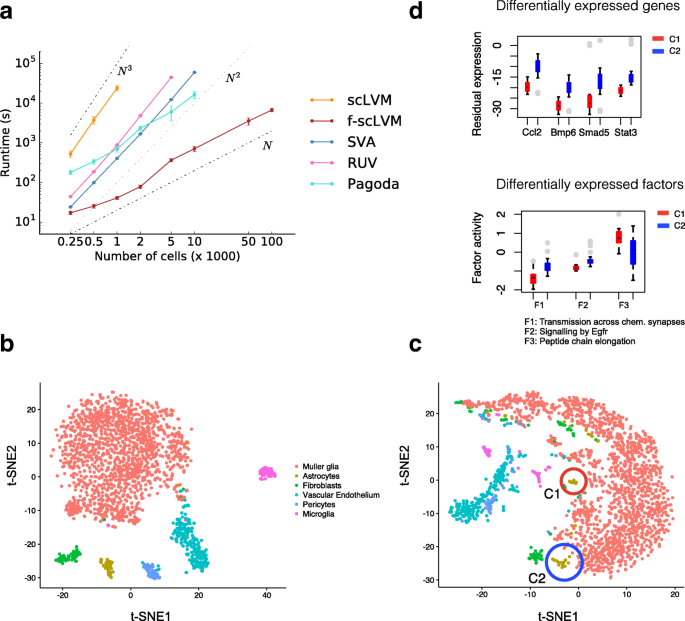
产品关联:文献未提及具体实验产品,领域常规使用高通量单细胞数据分析工具(如Drop-seq Tools)处理Drop-seq数据。
4. Biomarker研究及发现成果
Biomarker定位:本研究中的Biomarker包括两类,一是注释通路因子(如G2/M检查点、P53通路、肌肉收缩、先天免疫系统),作为细胞状态的转录组特征;二是未注释因子对应的细胞亚群特征(如星形胶质细胞的免疫活化亚群)。筛选与验证逻辑为:基于MSigDB、REACTOME等通路数据库的基因集注释构建初始因子,通过f-scLVM模型推断因子的相关性,数据驱动修正基因集注释,再通过细胞分群、差异表达分析验证因子的生物学意义。
研究过程详述:Biomarker的来源为单细胞RNA测序的基因表达矩阵,验证方法包括因子相关性分析、ROC曲线评估、细胞分群可视化、差异表达分析等。在小鼠胚胎干细胞数据中,G2/M检查点与P53通路因子区分细胞周期阶段的特异性与敏感性较高(AUC>0.9,n=182,P<0.001);在神经元细胞数据中,肌肉收缩因子能特异性区分内皮壁细胞,先天免疫系统因子能特异性区分小胶质细胞;在视网膜细胞数据中,星形胶质细胞亚群的差异基因富集于免疫反应过程,敏感性为80%左右(文献未明确提供具体数值,基于图表趋势推测)。
核心成果提炼:本研究发现了多个与细胞状态相关的转录组Biomarker,如G2/M检查点因子可作为细胞周期的特征标记,肌肉收缩因子可作为内皮壁细胞的特征标记;首次通过数据驱动修正了通路基因集注释,补充了多个已知的功能相关基因;在大样本数据中发现了星形胶质细胞的免疫活化亚群,其差异基因富集于BMP信号通路,为神经退行性疾病的研究提供了新的细胞亚群靶点。本研究的创新性在于将通路注释与因子分析结合,实现了Biomarker的精准识别与基因集的自动修正,且适配大样本数据集的高效分析,为单细胞转录组Biomarker研究提供了新的技术框架。