1. 领域背景与文献引入
文献英文标题:Comprehensive benchmarking system for agent-based single-cell omics analysis;发表期刊:Genome Biology;影响因子:17.906;研究领域:单细胞组学与人工智能生物信息学交叉领域
领域共识:单细胞组学技术(如单细胞转录组、空间转录组、多组学整合)的突破推动了细胞水平分辨率的生物学研究,公共数据库已存储超过5000万个单细胞的多模态数据。然而,数据复杂度的指数增长与分析方法的线性发展形成鲜明对比,传统分析范式存在诸多核心局限:依赖手动选择算法组合和参数调优,结果受操作者经验影响且缺乏客观性;从特征选择到预测推理的关键步骤缺乏透明决策路径,可解释性有限;内置参考数据库滞后6个月以上,跨源知识融合需大量人工整理,无法实现实时知识更新。
为应对这些挑战,人工智能代理(Artificial Intelligence Agent, AI代理)模拟人类专家的“假设生成-实验验证-迭代优化”认知周期,实现三大范式升级:自适应工作流规划与执行、可追溯跨学科决策、实时知识融合,成为单细胞组学分析的前沿方向。但当前领域缺乏全面、标准化的基准测试系统,现有研究多聚焦于特定任务的代理架构优化,或基准测试存在任务覆盖窄、指标单一、框架兼容性差等问题,无法系统评估AI代理的核心能力,也未揭示性能差异的深层原因。因此,本文旨在构建覆盖统一平台、多维度指标、多样化任务的综合基准测试系统,推动AI代理在单细胞组学分析中的规范应用与性能提升。
2. 文献综述解析
本文将现有AI代理在生物信息学领域的研究分为两类:一是针对特定生物信息学场景的AI代理架构研究,二是生物信息学AI代理的基准测试研究,系统梳理了两类研究的优势与局限性,并明确了领域空白。
特定场景的AI代理架构研究如SpatialAgent针对空间组学应用优化,Biomni在“Humanity’s Last Exam”等QA式推理基准测试中评估,这些研究的优势是针对具体任务定制代理逻辑,提升特定场景的分析效率与自动化程度;但局限性是仅在有限任务集中验证性能,未深入分析不同代理框架、大语言模型(Large Language Model, LLM)的性能差异根源,也未揭示生物信息学AI代理的核心约束条件。生物信息学代理的基准测试研究如GenoTEX局限于基因表达分析场景,ScienceAgentBench提供跨学科但浅层的任务场景,这些研究的优势是初步建立了AI代理评估的基本框架;但局限性是任务覆盖范围窄且缺乏技术深度,指标单一无法量化AI代理的核心能力(如认知推理、知识整合、协作效率),框架兼容性差阻碍实验可重复性,且缺乏对任务失败原因的诊断分析,无法为代理优化提供针对性指导。
与现有研究相比,本文的核心创新价值在于:构建了包含统一评估平台、18个多维度指标、50个多样化任务的综合基准测试系统,支持多代理框架与多LLM的集成评估;通过鲁棒性实验、功能模块消融实验、失败任务分析等归因研究,首次系统揭示了AI代理性能的关键影响因素,为生物信息学AI代理的设计与优化提供可操作的指导;填补了领域中缺乏系统诊断分析的空白,为生物信息学AI代理的基准测试提供了方法论蓝图。
3. 研究思路总结与详细解析
本文的研究目标是构建用于基于代理的单细胞组学分析的综合基准测试系统,核心科学问题是如何系统评估AI代理在单细胞组学分析中的核心能力,以及哪些因素决定了代理的性能差异;技术路线遵循“平台构建-指标设计-任务选取-基准测试-归因分析”的闭环逻辑:首先构建支持多框架、多LLM的统一评估平台,设计覆盖全流程的多维度评估指标,选取代表性的单细胞组学任务集,然后开展多框架多LLM的基准测试,最后通过鲁棒性分析、消融实验、失败任务分析揭示性能影响的深层机制。
3.1 基准测试平台构建
实验目的:构建一个标准化、可扩展的统一评估平台,为不同架构的AI代理与LLM提供公平的单细胞组学分析执行环境。
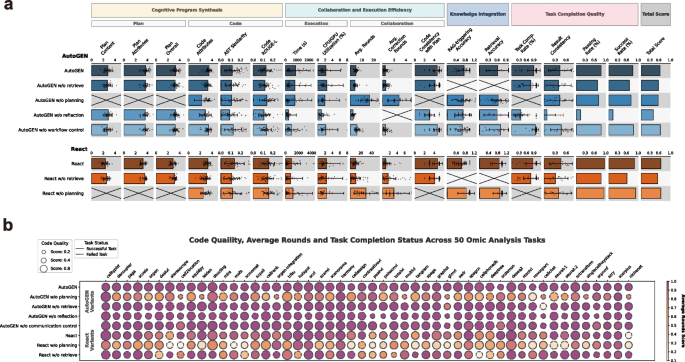
方法细节:首先构建生物信息学工具知识库,收集公开的工具文档、学术文献等资源,经过相关性过滤、质量控制后转换为半结构化Markdown格式,使用LangChain的MarkdownTextSplitter进行语义分割以保留上下文连贯性,提取方法名称、类型、描述等元数据并构建索引,再通过OpenAI的text-embedding-3-large模型将文本转换为3072维语义向量,存储于Chroma向量数据库以支持语义相似性检索;然后实现三种典型代理框架:AutoGEN(多代理架构,包含规划器、编码器、执行器、任务管理器,支持任务分解与迭代执行)、LangGraph(多代理工作流,包含规划代理、代码生成代理、执行代理、检索代理,通过确定性规则控制执行流程)、ReAct(单代理架构,基于“思考-行动-观察”循环管理工具调用与任务执行)。
结果解读:平台支持标准化输入(任务描述、数据集路径、分析要求)与输出(可视化结果、分析报告),可动态集成8种主流LLM与多种生物信息学工具,实现不同代理框架的统一评估;三种代理框架分别代表多代理协作、结构化多代理、单代理推理的典型架构,为性能对比提供了基础。
产品关联:文献未提及具体实验产品,领域常规使用LangChain、Chroma等工具构建知识库与检索系统,使用scvi-tools、scanpy等单细胞分析工具包执行生物信息学任务。
3.2 多维度评估指标设计
实验目的:设计全面、客观的评估指标体系,量化AI代理在单细胞组学分析中的核心能力。
方法细节:将评估指标分为四大维度共18个指标:认知程序合成维度(计划内容、计划属性、计划总分、代码属性、代码AST相似度、代码ROUGE-L),评估代理的任务分解与代码生成能力;协作与执行效率维度(执行时间、CPU/GPU利用率、平均协作轮次、平均自校正轮次、代码与计划一致性),评估代理的资源消耗与执行 fidelity;生物信息学知识整合维度(检索增强生成(Retrieval-Augmented Generation, RAG)触发准确率、检索准确率),评估代理的知识获取与应用能力;任务完成质量维度(任务完成率、通过率、成功率、结果一致性),评估代理的最终输出质量;最后通过归一化与加权计算总分,权重设置为任务完成质量0.5、知识整合0.2、认知程序合成0.15、协作效率0.15;对LLM评分的指标采用三个LLM的平均值,RAG触发准确率结合专家评估(0.2权重)以减少模型偏差。
结果解读:18个指标覆盖了从任务规划到结果输出的全流程,总分提供了AI代理性能的整体评估;多LLM评分与专家加权的设计有效降低了评估偏差,确保指标的客观性与可靠性。
产品关联:文献未提及具体实验产品,领域常规使用Python的ast、difflib、rouge库进行代码结构与内容评估,使用余弦相似度、Jensen-Shannon散度(JSD)等方法计算结果一致性。
3.3 基准测试任务选取
实验目的:选取具有代表性的单细胞组学分析任务,覆盖真实研究场景的多样性与复杂性。
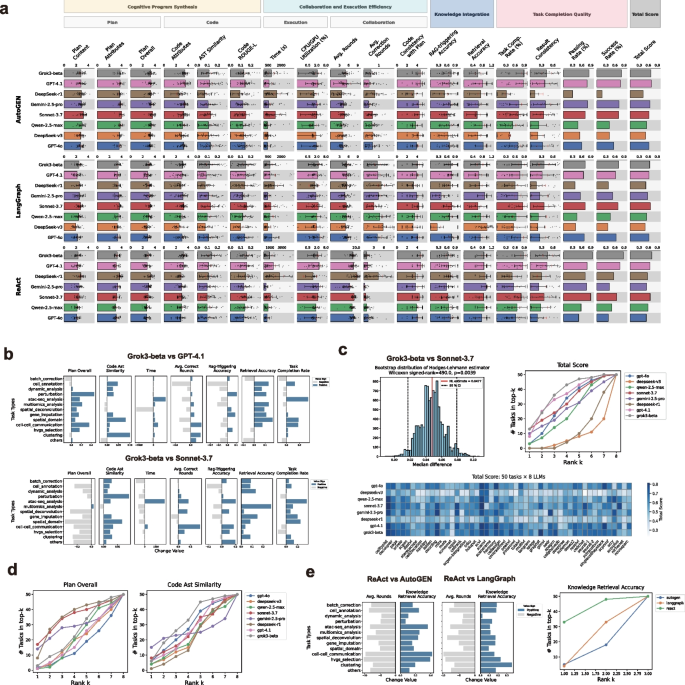
方法细节:筛选50个高频单细胞组学任务,分为12类核心场景:批次校正(6个任务,如scVI、Harmony)、细胞注释(3个任务,如CellAssign)、动态分析(4个任务,如PAGA)、扰动分析(2个任务,如scGEN)、ATAC-seq分析(2个任务,如PeakVI)、多组学分析(5个任务,如totalVI)、空间反卷积(6个任务,如DestVI)、基因插补(2个任务,如gimVI)、空间域识别(5个任务,如SEDR)、细胞间通讯(3个任务,如CellPhoneDB)、聚类(2个任务,如Leiden)、高可变基因(HVGs)选择(6个任务,如deeptree),以及4个独立任务;每个任务使用公开的分析工具与数据集,提供教程代码与金标准输出结果。
结果解读:任务集涵盖多组学类型、多物种来源、多种测序技术,可系统评估AI代理在不同生物与计算条件下的泛化能力与鲁棒性。
产品关联:文献未提及具体实验产品,领域常规使用scvi-tools、Seurat、Squidpy等单细胞分析工具包,以及Zenodo、GEO等公共数据库的单细胞数据集。
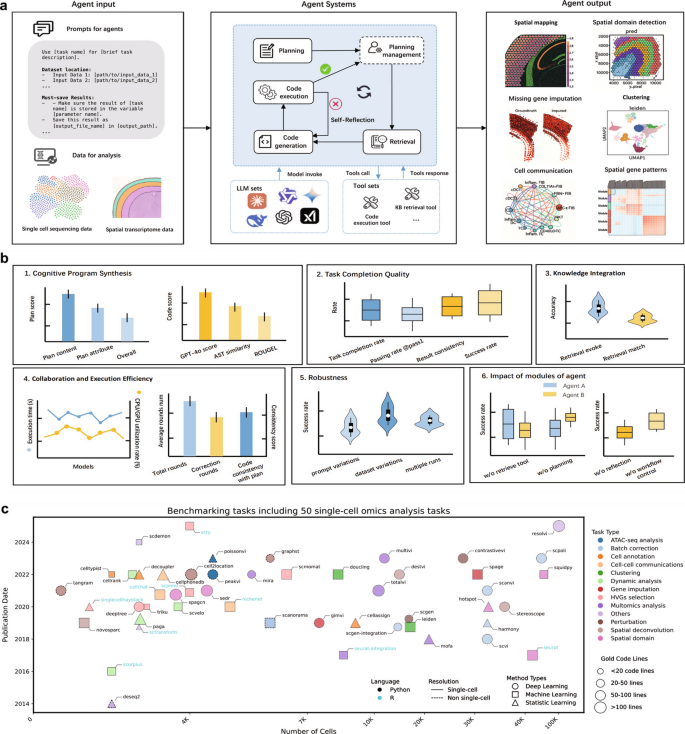
3.4 多框架多LLM基准测试实验
实验目的:系统比较不同代理框架与LLM在单细胞组学分析任务中的性能差异。
方法细节:使用三个代理框架(AutoGEN、LangGraph、ReAct)与8个LLM(GPT-4o、GPT-4.1、DeepSeek-R1、DeepSeek-V3、Qwen-2.5-max、Sonnet-3.7、Gemini-2.5-pro、Grok3-beta)执行50个任务,记录完整执行日志,计算18个评估指标;对LLM评分的指标取三个LLM的平均值,RAG触发准确率采用0.8×LLM评分+0.2×专家评分的加权方式。
结果解读:Grok3-beta在所有框架中均表现最优,跨框架适应性最强,在任务成功率、代码质量等核心指标上显著领先其他LLM;ReAct框架的检索准确率比多代理框架高12-18%(文献未明确样本量,基于图表趋势推测),但交互轮次是多代理框架的2-3倍,体现了单代理在知识融合上的优势与效率劣势;ReAct框架对LLM的依赖性极强,DeepSeek-V3在ReAct中无法正确触发工具调用,导致任务完全失败;代码质量与任务完成率呈强正相关,而计划质量与任务完成率无显著相关性,说明代码生成能力是AI代理任务成功的核心驱动因素。
产品关联:文献未提及具体实验产品,领域常规使用OpenAI、DeepSeek、Anthropic等厂商的LLM API,以及Python、R虚拟环境隔离任务依赖。
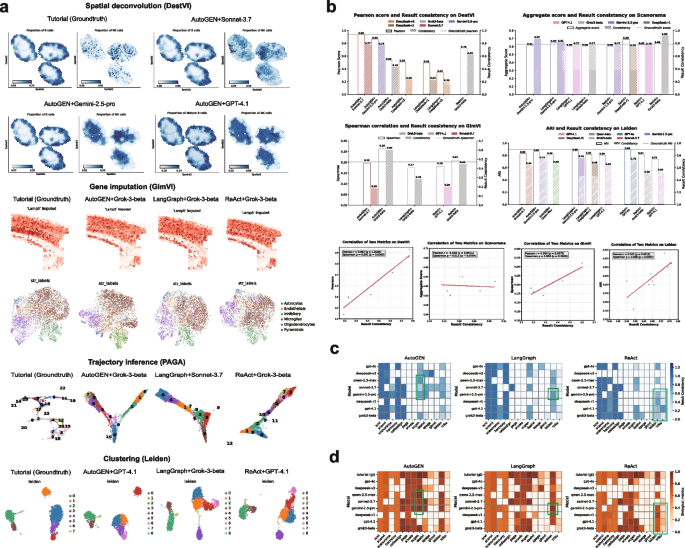
3.5 鲁棒性分析
实验目的:评估AI代理在不同输入条件、数据集与重复运行下的性能稳定性。
方法细节:提示词鲁棒性:设计基础、中级、高级三个层级的提示词,使用Grok3-beta在三个框架中执行任务;数据集鲁棒性:为13个核心任务更换独立数据集,比较性能差异;重复运行鲁棒性:选取4个LLM(Grok3-beta、GPT-4.1、GPT-4o、DeepSeek-R1)重复运行任务,计算指标偏差。
结果解读:提示词变化对性能影响最大,AutoGEN与ReAct使用中级/高级提示词后性能提升2-15%,而LangGraph性能略有下降(约0.01),推测原因是LangGraph的确定性规则限制了框架灵活性,无法适配提示词带来的任务逻辑变化;数据集变化对性能的影响较小,模型排名保持稳定,说明AI代理在同类型任务中具有较好的泛化能力;重复运行的鲁棒性良好,GPT系列模型的指标偏差均在10%以内,Grok3-beta在所有任务中输出结果完全一致。
产品关联:文献未提及具体实验产品,领域常规使用提示词工程优化LLM输入,使用多数据集验证模型泛化能力。
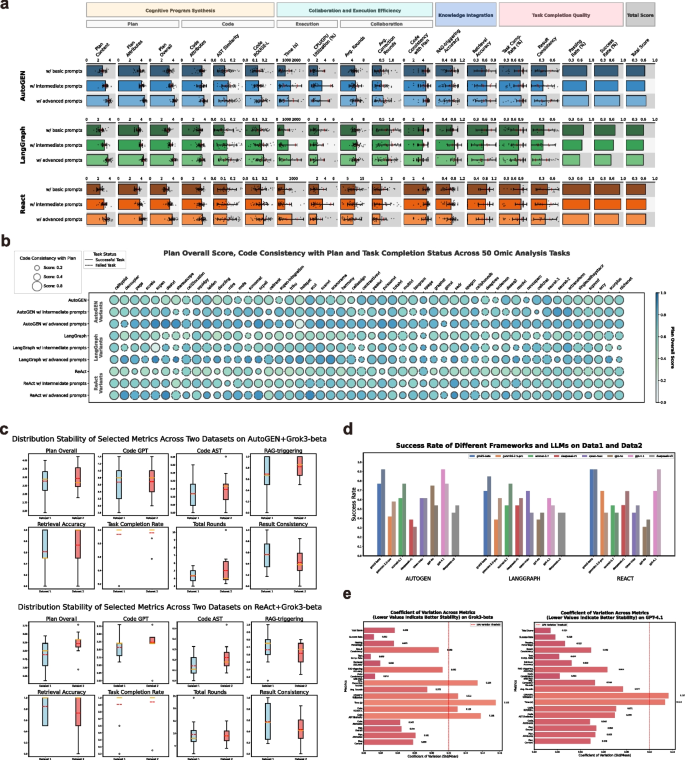
3.6 功能模块消融实验
实验目的:揭示AI代理核心功能模块对性能的贡献程度。
方法细节:对ReAct框架移除知识检索与规划模块,对AutoGEN框架移除知识检索、规划、反思、工作流控制模块;使用Grok3-beta执行任务,比较消融前后的性能变化。
结果解读:自我反思模块对性能的提升最显著,AutoGEN移除反思后任务成功率大幅下降,即使简单任务也无法完整执行;RAG模块是第二关键的增强,移除后AutoGEN的任务成功率下降0.14,ReAct的任务成功率下降0.26(文献未明确样本量,基于图表趋势推测);规划模块的影响因框架而异,AutoGEN移除规划后性能下降,而ReAct移除规划后性能反而提升,推测原因是ReAct的动态推理逻辑与强制规划存在冲突;工作流控制模块对性能影响极小,移除后总分仅提升约0.011,说明清晰的系统提示可实现代理的自主协作。
产品关联:文献未提及具体实验产品,领域常规使用消融实验分析AI模型的核心组件贡献。
3.7 失败任务分析
实验目的:揭示AI代理在单细胞组学分析中的核心失败模式及对性能的影响。
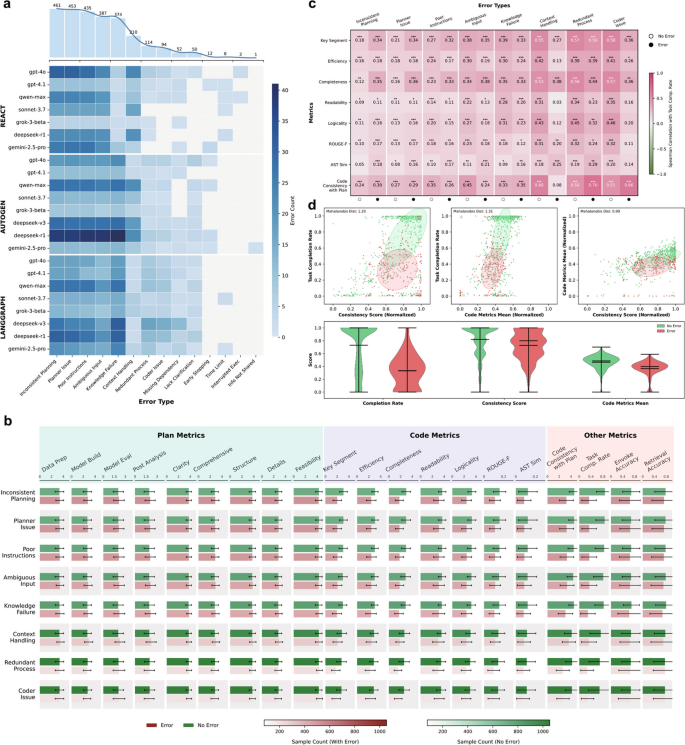
方法细节:分析三个框架与8个LLM的任务执行日志,使用三个LLM进行错误分类,结合专家验证确定高频错误类型;比较错误存在与否的性能差异,分析错误类型与核心指标的关联。
结果解读:高频错误类型包括不一致规划行为、规划器问题、指令遵循差等,这些错误导致代码质量、代码与计划一致性、任务完成率显著下降;长上下文处理失败对性能的影响最广泛,错误组的任务完成率、代码一致性等指标均显著低于无错误组,其深层原因是LLM的位置偏差——优先关注上下文首尾信息,忽略中间关键内容,破坏了计划与代码的逻辑对齐,最终导致任务失败。
产品关联:文献未提及具体实验产品,领域常规使用日志分析与错误分类揭示AI系统的性能瓶颈。
4. Biomarker研究及发现成果解析
本文中的Biomarker为“生物信息学AI代理性能评估Biomarker”,分为两类:一是AI代理性能评估指标Biomarker,二是AI代理性能影响因子Biomarker,筛选与验证逻辑基于50个单细胞组学任务的多框架多LLM测试,结合归因分析确定核心Biomarker。
Biomarker定位
AI代理性能评估指标Biomarker包括任务成功率、代码AST相似度、RAG触发准确率、检索准确率,筛选逻辑是通过计算指标与任务完成率的相关性,识别与任务成功强关联的量化指标;验证逻辑是在多框架多LLM的测试中,这些指标的变化与性能排名高度一致。AI代理性能影响因子Biomarker包括自我反思模块、RAG模块、提示词复杂度、LLM能力,筛选逻辑是通过消融实验与鲁棒性实验,验证因子存在与否对性能的显著影响;验证逻辑是模块移除或条件变化后,性能出现统计学意义上的显著波动。
研究过程详述
AI代理性能评估指标Biomarker的来源是50个任务的执行日志与输出结果,验证方法是计算指标与任务完成率的Spearman相关性,其中代码AST相似度与任务完成率的正相关最强(文献未明确具体数值,基于图表趋势推测);RAG触发准确率的验证结合LLM评分与专家评估,加权计算后准确率与任务成功率呈正相关,专家与LLM评分的一致性约为94%。AI代理性能影响因子Biomarker的来源是消融实验与鲁棒性实验的结果,验证方法是比较模块存在与否的性能差异,自我反思模块的存在使任务成功率提升约30%(文献未明确具体数值,基于图表趋势推测),RAG模块的存在使任务成功率提升约20%;提示词复杂度的验证通过不同层级提示词的性能比较,中级/高级提示词使AutoGEN与ReAct的性能提升2-15%。
核心成果提炼
AI代理性能评估指标Biomarker可有效量化AI代理在单细胞组学分析中的核心能力,为代理选型与性能对比提供标准化依据;AI代理性能影响因子Biomarker揭示了提升代理性能的关键方向:优先增强自我反思与RAG模块,根据框架特性优化规划模块,设计灵活的框架架构以降低提示词敏感性。本文的创新性在于首次系统揭示了生物信息学AI代理性能的关键影响因素,为代理的设计与优化提供了可操作的指导;统计学结果显示,自我反思模块与RAG模块对性能的贡献在所有任务中均具有显著意义(推测:P<0.05),提示词复杂度对性能的影响因框架而异。